DDIA Chapter 7. Transactions
Buy the book https://dataintensive.net/
Intro
- Definition: transactions is a way for an application to group several reads and writes together into a logical unit, either the entire transaction succeeds (commit) or it fails (abort, rollback)
- Purpose: simplify the programming model for applications accessing a database
- Main question: how to figure out need for transactions?
- Prerequisite: understand transaction safety guarantees and costs
- Go deep in concurrency control: discuss race conditions and databases isolation levels
- This chapter applies to both single-node and distributed databases, [[DDIA-8 The Trouble with Distributed Systems]] focuses on distributed systems
The Slippery Concept of a Transaction
- Transaction support introduced in 1975
- NoSQL rise in late 200s
- Offers choice of new data model ([[DDIA-2 Data Models and Query Languages]])
- Includes replication ([[DDIA-5 Replication]]) and partitioning ([[DDIA-6 Partitioning]]) by default
- Abandoned transactions or describe a much weaker set of guarantees
- Transactions have advantages and limitations - trade-offs!
The Meaning of ACID
- ACID: Atomicity, Consistency, Isolation, and Durability
- Database implementation does not equal
- BASE, which stands for Basically Available, Soft state, and Eventual consistency
- Even more vague, just say not ACID
Atomicity
- In general, atomic refers to something that cannot be broken down into smaller parts
- In the context of ACID, atomicity is not about concurrency, which is covered under the letter I, for isolation
- If the writes are grouped together into an atomic transaction, and the transaction cannot be completed (committed) due to a fault, then the transaction is aborted and the database must discard or undo any writes it has made so far in that transaction.
Consistency
Term is terribly overloaded:
- Eventual consistency: [[DDIA-5 Replication#Problems with Replication Lag]]
- Consistent hashing: [[DDIA-6 Partitioning#Partitioning by Hash of Key]]
- In CAP theorem, consistency means linearizability ([[DDIA-9 Consistency and Consensus#Linearizability]])
- In the context of ACID, consistency refers to an application-specific notion of the database being in a “good state.”
Atomicity, isolation, and durability are properties of the database, whereas consistency (in the ACID sense) is a property of the application, by relying on the database’s atomicity and isolation properties in order to achieve.
Isolation
- Isolation in the sense of ACID means that concurrently executing transactions are isolated from each other
- In practice, serializable isolation is rarely used for its performance penalty.
- Snapshot isolation is a weaker guarantee: [[#Weak Isolation Levels]]
Durability
- Durability: once a transaction has committed successfully, any data it has written will not be forgotten, even if there is a hardware fault or the database crashes.
- Single node: write to disk via WAL or similar ([[DDIA-3 Storage and Retrieval#Making B-trees reliable]])
- Replicated DB: data copied to some number of nodes, then report a transaction committed
- Perfect durability does not exist ([[DDIA-1 Reliable, Scalable, and Maintainable Applications#Reliability]])
Single-Object and Multi-Object Operations
- Multi-object transactions: keep pieces of data in sync when modifying several objects (rows, documents, records) at once
- Require some way of determining which read and write operations belong to the same transaction
- In relational DB, it's done based on client's TCP connection's
BEGIN TRANSACTIONandCOMMITstatements - Non-relational DBs usually don't have such a way of grouping -> may result in partially updated state
- In relational DB, it's done based on client's TCP connection's
Single-object writes
A transaction is usually understood as a mechanism for grouping multiple operations on multiple objects into one unit of execution. But we also need single-object writes:
- Atomicity: use a log for crash recovery ([[DDIA-3 Storage and Retrieval#Making B-trees reliable]])
- Isolation: use a lock on each object
- Increment operation or [[#Compare-and-set]]
The need for multi-object transactions
- Multi-object transactions are hard to implement and can hurt high availability and performance, but it is needed in several scenarios:
- Relational: ensure foreign key references remain valid
- Document: update denormalized information in several documents
- Secondary indexes: update indexes with value changes
- Discuss concurrency problems at [[#Weak Isolation Levels]] and alternatives in [[DDIA-12 The Future of Data Systems]]
Handling errors and aborts
- ACID databases philosophy: abandon transaction and safe retry when error occurred
- Leaderless replication datastores work on best-effort basis
- ORMs may not leverage transaction retry
- Caveats:
- Duplication
- Overload
- Only worth retry after transient errors
- Side effects and two-phase commit ([[DDIA-9 Consistency and Consensus#Atomic Commit and Two-Phase Commit 2PC]])
- Write dataloss during retry
Weak Isolation Levels
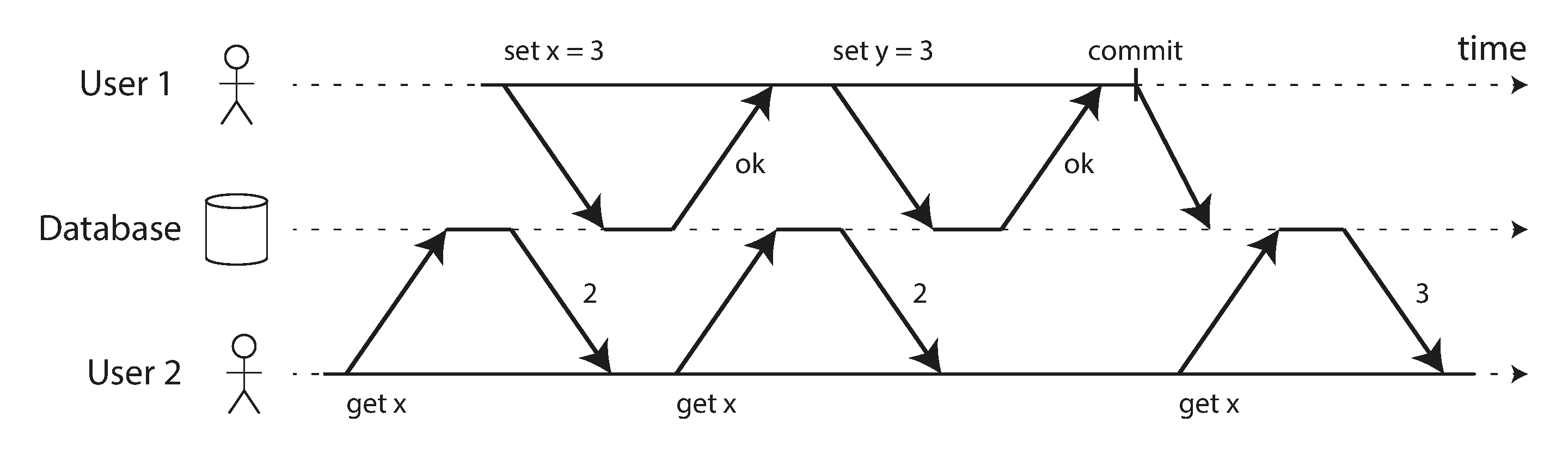
- Race conditions
- one transaction reads data that is being modified by another transaction
- two transactions try to modify same data
- serializable isolation means that the database guarantees that transactions have the same effect as if they ran serially
- Has a performance cost
- therefore use weaker levels of isolation
- ACID DBs also use weak isolation
Read Committed
- When reading from the database, you will only see data that has been committed (no dirty reads).
- When writing to the database, you will only overwrite data that has been committed (no dirty writes).
Implementing read committed
- Most commonly, databases prevent dirty writes by using row-level locks
- Using same lock to prevent dirty reads hurts latency of read-only transactions during one long-running write transaction
- Most databases instead remembers and responds with old value while write transaction is ongoing
Snapshot Isolation and Repeatable Read
- Read committed is not strong enough
- Anomaly read skew is an example of a nonrepeatable read, and is allowed under read committed isolation
- Note: the term skew also showed up in [[DDIA-6 Partitioning#Skewed Workloads and Relieving Hot Spots]]
- Example situations that cannot tolerate read skew inconsistency
- backups, analytic queries and integrity checks
- the key is long-running, read-only queries
- Common solution: Snapshot isolation that each transaction reads from a consistent snapshot of the database
- Supported by PostgreSQL, MySQL with the InnoDB storage engine, Oracle, SQL Server, and others
Implementing snapshot isolation
- Typically use write locks to prevent dirty writes
- From a performance point of view, a key principle of snapshot isolation is readers never block writers, and writers never block readers.
- multi-version concurrency control (MVCC)
- A typical approach is that read committed uses a separate snapshot for each query, while snapshot isolation uses the same snapshot for an entire transaction.
Visibility rules for observing a consistent snapshot
When a transaction reads from the database, transaction IDs are used to decide which objects it can see and which are invisible.
An object is visible if both of the following conditions are true:
- At the time when the reader’s transaction started, the transaction that created the object had already committed.
- The object is not marked for deletion, or if it is, the transaction that requested deletion had not yet committed at the time when the reader’s transaction started.
Indexes and snapshot isolation
- Option 1: have the index simply point to all versions of an object and require an index query to filter out any object versions that are not visible to the current transaction. Remove the index entry when old object versions are no longer visible to any transactions.
- Option 2: use an append-only/copy-on-write B-tree variant to create a new copy of parent pages up to the B-tree root. A background process does compaction and GC.
Repeatable read and naming confusion
- In Oracle it is called serializable, and in PostgreSQL and MySQL it is called repeatable read
- Snapshot isolation was not in 1975 definition of isolation levels, the repeatable read is superficially similar but very ambiguous
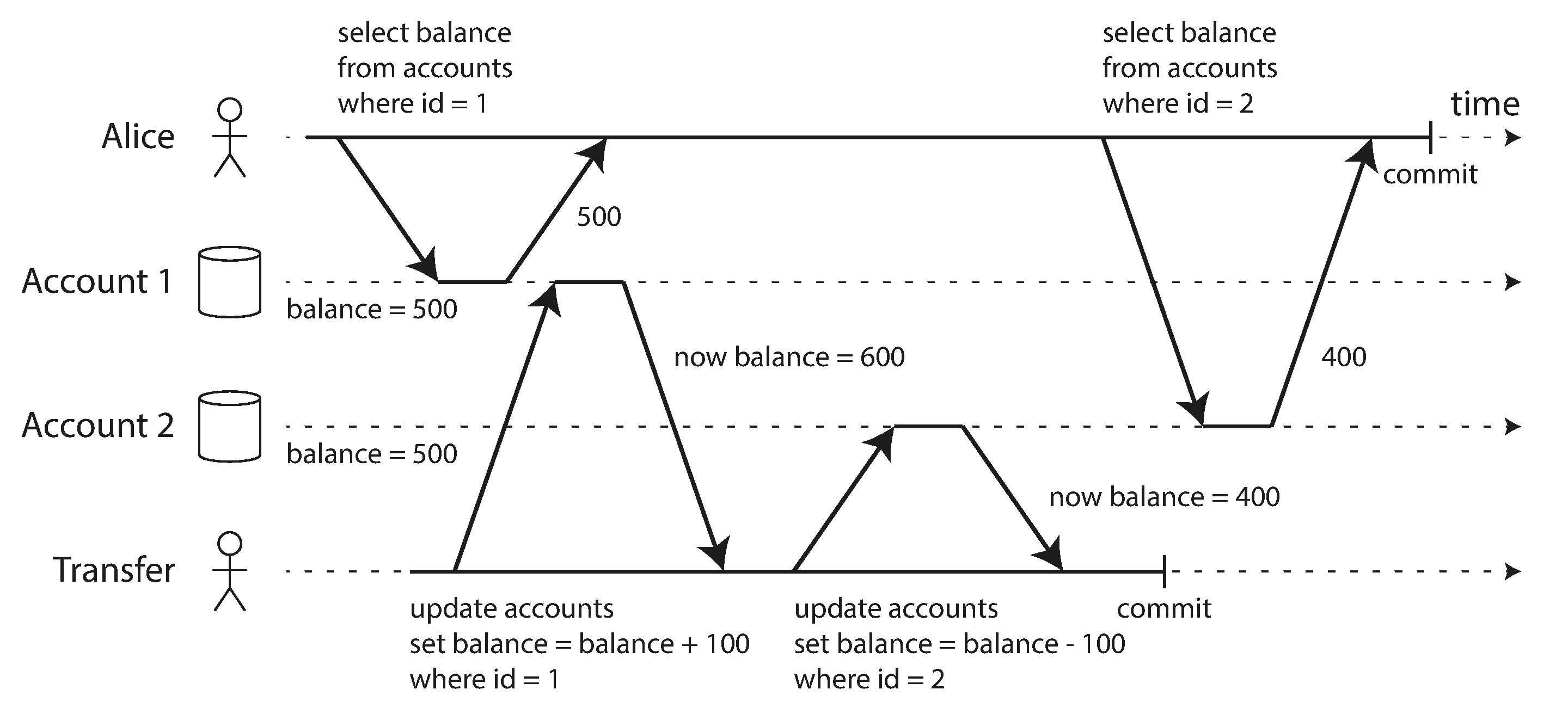
Preventing Lost Updates
- Read committed and snapshot isolation are guarantees of read-only transactions
- Other than dirty writes, there's also lost update problem
- When the second write does not include the first modification (clobbers)
Atomic write operations
- Relational DB concurrency-safe instruction:
UPDATE counters SET value = value + 1 WHERE key = 'foo'; - Document DBs provide atomic operations
- Redis provides atomic operations for modifying certain data structures (priority queue)
- Usually best choice, but not all can use atomic operations, e.g., editing a wiki page
- Implemented with an exclusive lock when an object is read, A.K.A. cursor stability
- Alternative approach is to force a single thread for atomic operations
Explicit locking
- If databases built-in is not sufficient, application needs to explicitly lock objects that are going to be updated.
- Example: SQL
FOR UPDATEclause
Automatically detecting lost updates
- Allow concurrent writes, and if the transaction manager detects a lost update, abort the transaction and force it to retry its read-modify-write cycle.
- An advantage of this approach is that databases can perform this check efficiently in conjunction with snapshot isolation.
- MySQL/InnoDB’s repeatable read does not detect lost update
Compare-and-set
- If the current value does not match what you previously read, the update has no effect, and the read-modify-write cycle must be retried
- But need to check whether your database’s compare-and-set operation is safe before relying on it.
Conflict resolution and replication
- Locks and compare-and-set operations assume that there is a single up-to-date copy of the data. This is not true in multi-leader and leaderless replication databases. (Revisit in [[DDIA-9 Consistency and Consensus#Linearizability]])
- Instead, a common approach is to allow siblings and use application code or special data structure to resolve and merge
- Atomic operations can work well in a replicated context especially if they are commutative.
- LWW loses data but is the default in many replicated databases.
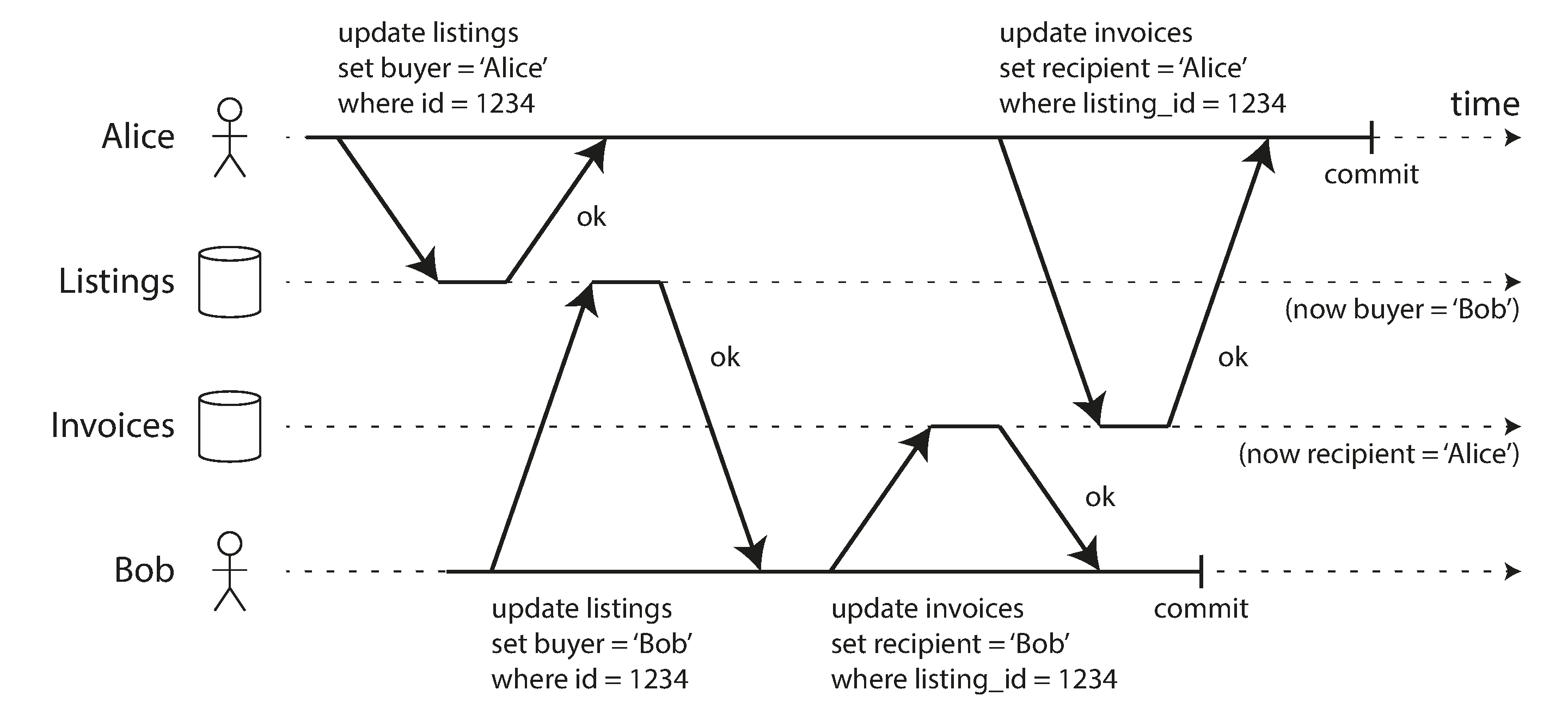
Write Skew and Phantoms
Characterizing write skew
- It is a generalization of the lost update problem
- Occurs if two transactions read the same objects, and then update some of those objects
- In the special case where different transactions update the same object, you get a dirty write or lost update anomaly
- If you can’t use a serializable isolation level, the second-best option in this case is probably to explicitly lock the rows that the transaction depends on.
More examples of write skew
- Meeting room booking system: time span overlapping
- Snapshot isolation does not prevent, need serializable isolation
- Multiplayer game: move two different figures to the same position
- Claiming a username
- Unique constraint is a simple solution
- Preventing double-spending: that causes more than allowed
Phantoms causing write skew
Similar pattern:
SELECTchecks some requirement by searching for rows that match- Continue based on result of the query
- If continue, application makes a write and commits the transaction. The effect of the write changes the step 1 query result. (This is called a phantom)
Snapshot isolation avoids phantoms in read-only queries.
Materializing conflicts
- materializing conflicts takes a phantom and turns it into a lock conflict on a concrete set of rows that exist in the database
- But it is hard and error-prone
- It is ugly that a concurrency control mechanism leak into the application data model
- A serializable isolation level is much preferable in most cases
Serializability
Problems of preventing race conditions with isolation levels:
- Hard to understand isolation levels
- Hard to tell whether application code is safe to run at a particular islation level
- No good tools to help detect race conditions (static analysis research)
The recommendation from researchers is to use serializable isolation, the strongest level. The database prevents all possible race conditions.
[[DDIA-9 Consistency and Consensus]] discusses geenralizing serializability to a distributed system.
Actual Serial Execution
- Every transaction must be small and fast for performance.
- It is limited to use cases where the active dataset can fit in memory for performance.
- Write throughput must be low enough to be handled on a single CPU core, or else transactions need to be partitioned without requiring cross-partition coordination.
- Cross-partition transactions are possible, but there is a hard limit to the extent to which they can be used.
History
- Causes for rethink around 2007:
- RAM becomes cheap enough
- Realized OLTP transactions are usually short ([[DDIA-3 Storage and Retrieval#Transaction Processing or Analytics]])
- Implemented in VoltDB/H-Store, Redis, and Datomic
Encapsulating transactions in stored procedures
Taking out human from critical path to avoid long waiting time, transactions have continued to be executed in an interactive client/server style. Network time is the throughput bottleneck.
Therefore, systems with single-threaded serial transaction processing don’t allow interactive multi-statement transactions. The application must submit the entire transaction code to the database ahead of time, as a stored procedure.
Pros and cons of stored procedures
Modern implementations supports general language, e.g., Redis uses Lua. Combined with in-memory dat, executing all transactions on single-thread is now feasible.
Partitioning
- Find a way of partitioning data so that each transaction only needs to read and write data within a single partition
- Then each partition can have its own transaction processing thread running independently from the others
- Allow transaction throughput to scale linearly with the number of CPU cores
- But cross-partition transactions are orders of magnitude below single-partition thoughput (note: but still reasonably fast). Source: https://dzone.com/articles/debunking-myths-about-voltdb
- Data with secondary indexes require lots of cross-partition coordination ([[DDIA-6 Partitioning#Partitioning and Secondary Indexes]])
Two-Phase Locking (2PL)
In 2PL, writers don’t just block other writers; they also block readers and vice versa. Snapshot isolation has the mantra readers never block writers, and writers never block readers ([[#Implementing snapshot isolation]])
Implementation of two-phase locking
- Readers acquire shared mode lock, writers acquire exclusive mode lock
- shared lock blocks writer acquiring exclusive lock
- Release lock when committing the transaction
- Database detects deadlock and application retries aborted transaction
Performance of two-phase locking
- Overhead of acquiring and releasing all those locks
- Reduced concurrency
- Result in unstable latencies and very slow at high percentiles
- Aborted transactions mean wasted effort
- Deadlock happens more frequently under 2PL than lock-based read committed
Predicate locks
How to fix [[#Phantoms causing write skew]]? The key idea here is that a predicate lock applies even to objects that do not yet exist in the database, but which might be added in the future (phantoms).
Index-range locks
- Problem: checking for matching locks becomes time-consuming
- Solution: simplified approximation of predicate locking, can fall back to a shared lock on the entire table
Serializable Snapshot Isolation (SSI)
- Goal of SSI: full serializability with small perf penalty compared to snapshot isolation
- Used in single-node (PostgreSQL 9.1) and distributed, may become the new default
Pessimistic versus optimistic concurrency control
- 2PL is pessimistic
- SSI is optimistic: When a transaction wants to commit, the database checks isolation violations
- If there is enough spare capacity, and if contention between transactions is not too high, optimistic concurrency control techniques perform better
- On top of snapshot isolation, SSI adds an algorithm for detecting serialization conflicts among writes and determining which transactions to abort.
Decisions based on an outdated premise
A premise is a fact that was true at the beginning of the transaction. How does the database know if a query result might have changed?
Detecting stale MVCC reads
- The database needs to track when a transaction ignores another transaction’s writes due to MVCC visibility rules.
- Check any of the ignored writes has been committed and abort if so.
- Wait until committing because read-only won't write skew, and other write transactions might be aborted
- Key is to avoid unnecessary aborts
Detecting writes that affect prior reads
- DB track ephemeral information about transactions reading data on index, or at the table level
- When a transaction writes, notify existing reader of that data
- Check other writes commit when commit reader
- (Question: why not notify existing reader when committing the other writer transaction?)
Performance of serializable snapshot isolation
The rate of aborts significantly affects the overall performance of SSI. So SSI requires short read-write transactions, but it's less sensitive to slow transactions than two-phase locking or serial execution.