DDIA Chapter 6. Partitioning
Buy the book https://dataintensive.net/
Intro
- Definition: A partition is a division of a logical database or its constituent elements into distinct independent parts.
- Main reason: scalability - the query load can be distributed across many processors.
Partitioning and Replication
- Partitioning is usually combined with replication so that copies of each partition are stored on multiple nodes.
- A node may store more than one partition.
- [[DDIA-5 Replication]] applies to replication of partitions
Partitioning of Key-Value Data
- If the partitioning is unfair, so that some partitions have more data or queries than others, we call it skewed
- A partition with disproportionately high load is called a hot spot.
- Key-value data model: you always access a record by its primary key
Partitioning by Key Range
- Assign a continuous range of keys to each partition
- Pro: range scan is easier, data locality
- The ranges of keys are not necessarily evenly spaced
- Used by Bigtable, HBase, RethinkDB and MongoDB pre-v2.4
- Cons: certain access patterns can lead to hot spots (timestamp)
- Cons: finding split points and managing rebalancing is hard
Partitioning by Hash of Key
- A good hash function takes skewed data and makes it uniformly distributed.
- hash function need not be cryptographically strong (MD5, Murmur3, etc.)
- Assign each partition a range of hashes
- Consistent hashing, Rendezvous hashing
- Cannot do efficient range queries
- Cassandra compromise: compound primary key only the first part is hashed
- Cassandra one-to-many data model example:
(user_id, update_timestamp)
Skewed Workloads and Relieving Hot Spots
- Hashing a key cannot avoid hot spots
- Example: 3% of Twitter's Servers Dedicated to Justin Bieber
- Application has to reduce the skew by further partitioning and do additional work at read
Partitioning and Secondary Indexes
- The situation becomes more complicated if secondary indexes are involved (see also [[DDIA-3 Storage and Retrieval#Other Indexing Structures]]
- Secondary indexes are common in both relational and document DBs, and is the most important part of search servers (Solr, Elasticsearch)
- Main problem: secondary indexes don't map neatly to partitions
- Two main approaches:
- document-based partitioning
- term-based partitioning
Partitioning Secondary Indexes by Document
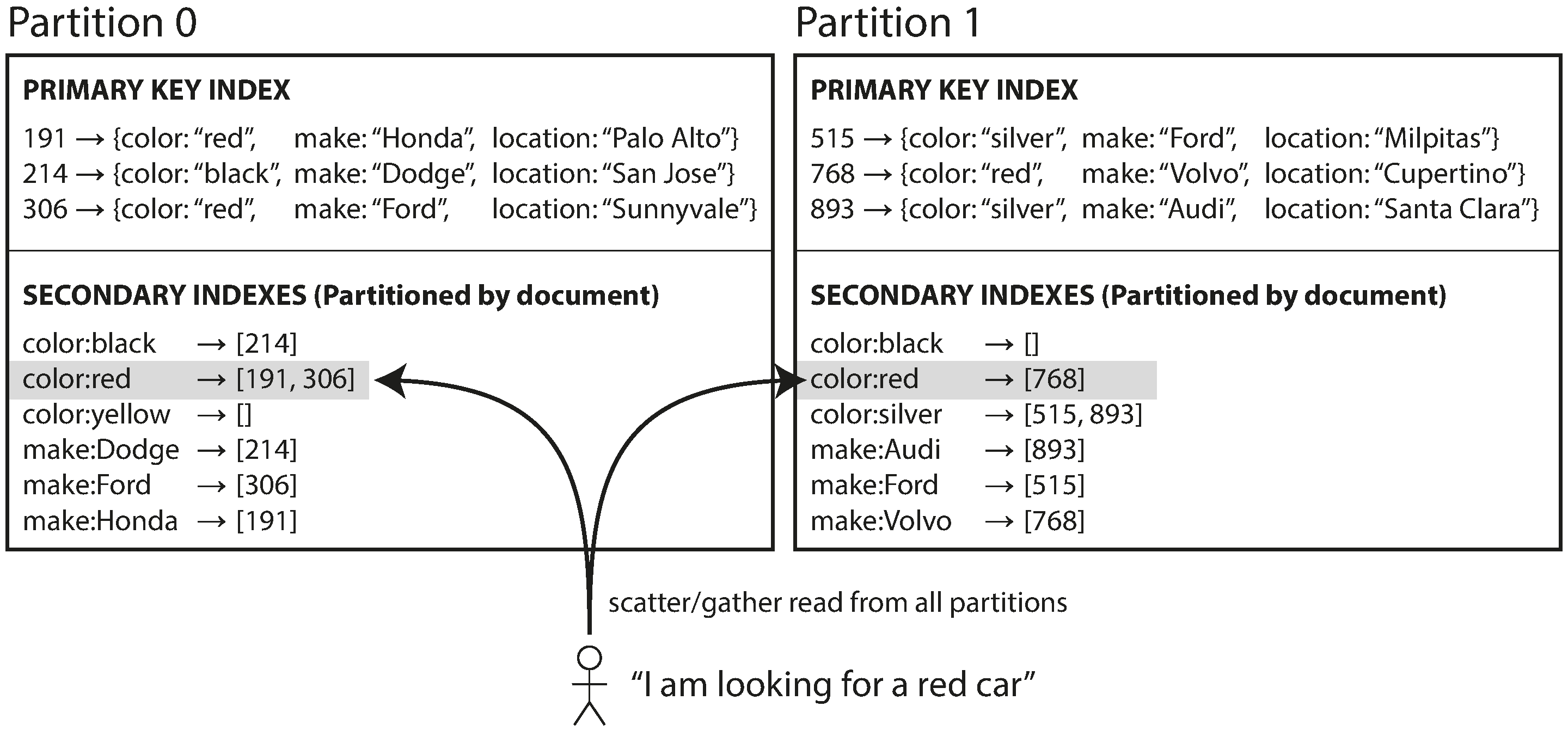
- Database can perform indexing automatically
- Note: in KV-only DB, application level secondary indexing is prone to inconsistency
- Each partition maintains its own secondary indexes
- A.K.A. local index
- Need to send the query to all partitions, and combine all the results you get back (scatter/gather)
- Read queries are expensive, and prone to latency amplification
- But widely used
- Recommend structure the partitioning scheme so that secondary index queries can be served from a single partition
Partitioning Secondary Indexes by Term
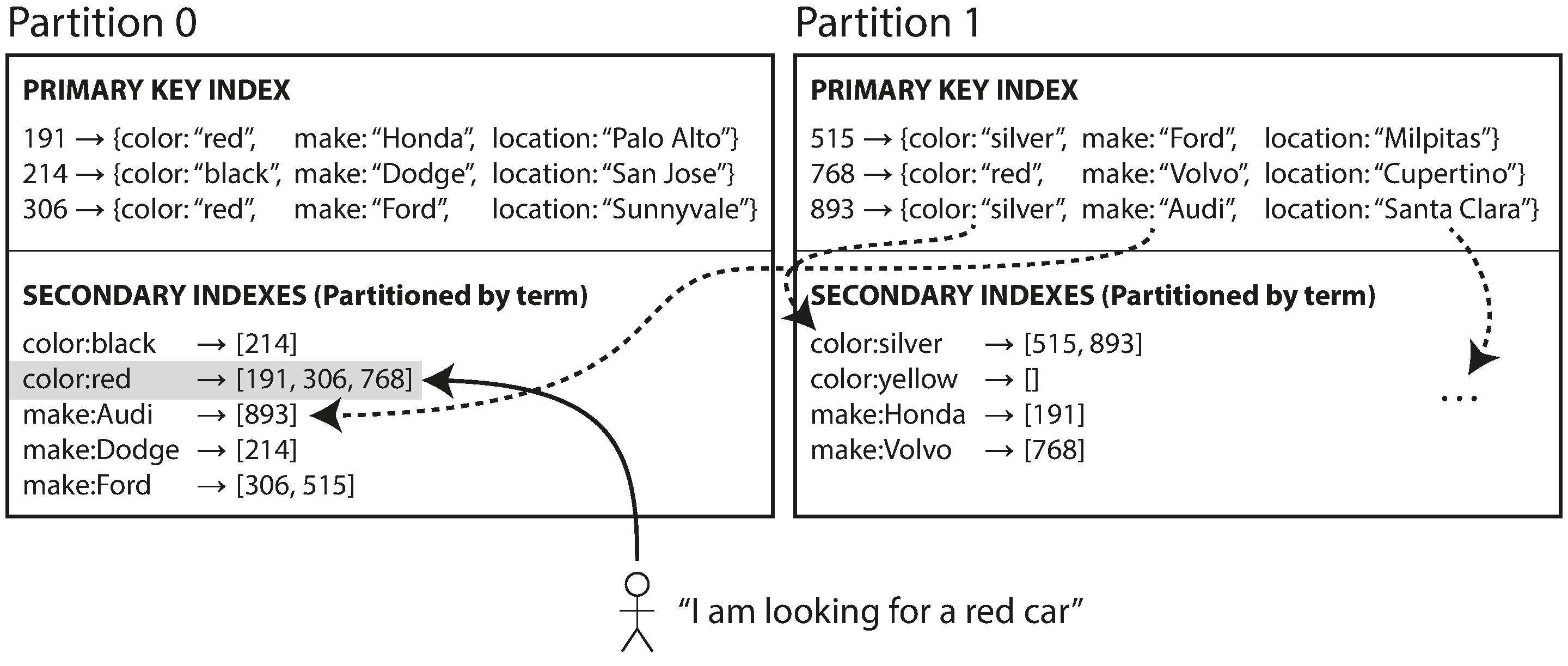
- A global index must also be partitioned (term-partitioned)
- Partition the index by the term itself, or using a hash of the term
- Pro: more efficient read (no scatter/gather)
- Con: write slower and more complicated, require distributed transaction
- Updates to global secondary indexes are asynchronous, e.g., Amazon DynamoDB
Rebalancing Partitions
- The process of moving load from one node in the cluster to another is called rebalancing.
- Minimum requirements:
- After rebalancing, the load (data storage, read and write requests) should be shared fairly between the nodes in the cluster.
- While rebalancing is happening, the database should continue accepting reads and writes.
- No more data than necessary should be moved between nodes, to make rebalancing fast and to minimize the network and disk I/O load.
Strategies for Rebalancing
How not to do it: hash mod N
Problem: move data more than necessary
Fixed number of partitions
- Create many more partitions than there are nodes, and assign several partitions to each node
- The new node can steal a few partitions from every existing node
- The number of partitions is usually fixed when the database is first set up and not changed afterward
- If partitions are very large, rebalancing and recovery from node failures become expensive. But if partitions are too small, they incur too much overhead
Dynamic partitioning
- Reason: reconfiguring key range partition boundaries manually is tedious
- Split when exceed or merge when shrink, similar to top level of a B-tree
- Partition transfer to another node
- Pre-splitting requires you already know what the key distribution looks like
- Also suits hash partitioning, e.g., MongoDB v2.4
Partitioning proportionally to nodes
- Fixed number of partitions per node
- Used by Cassandra and Ketama
- Cassandra 3.0 introduced an alternative rebalancing algorithm that avoids unfair splits
Operations: Automatic or Manual Rebalancing
- Fully automatic rebalancing: convenient but dangerous
- Fully manual
- Couchbase, Riak, and Voldemort generate a suggested partition assignment automatically, but require an administrator to commit it before it takes effect.
Request Routing
- An instance of more generalized problem: service discovery
- Open source solutions
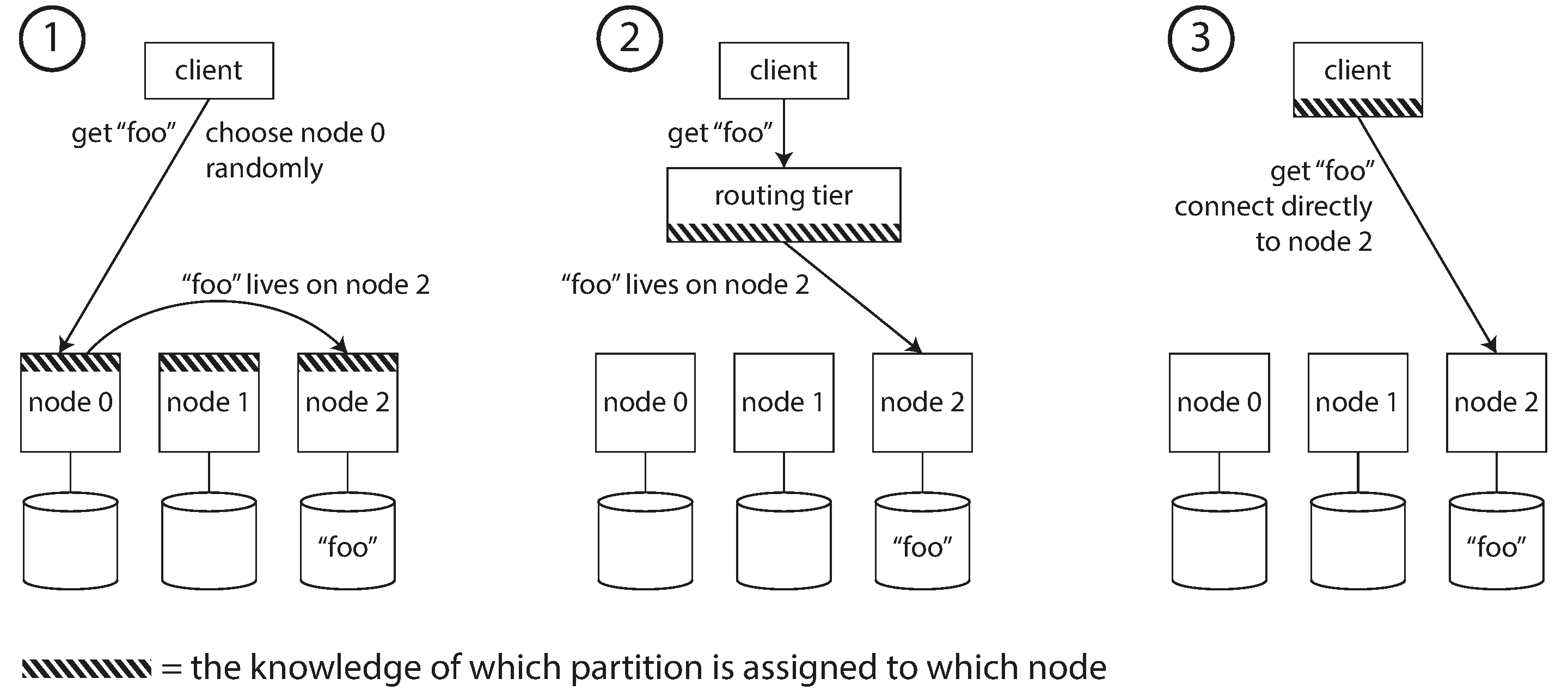
- On a high level, there're three approaches
- Hard to implement correctly the protocols for achieving consensus in a distributed system
- Separate coordination service such as ZooKeeper
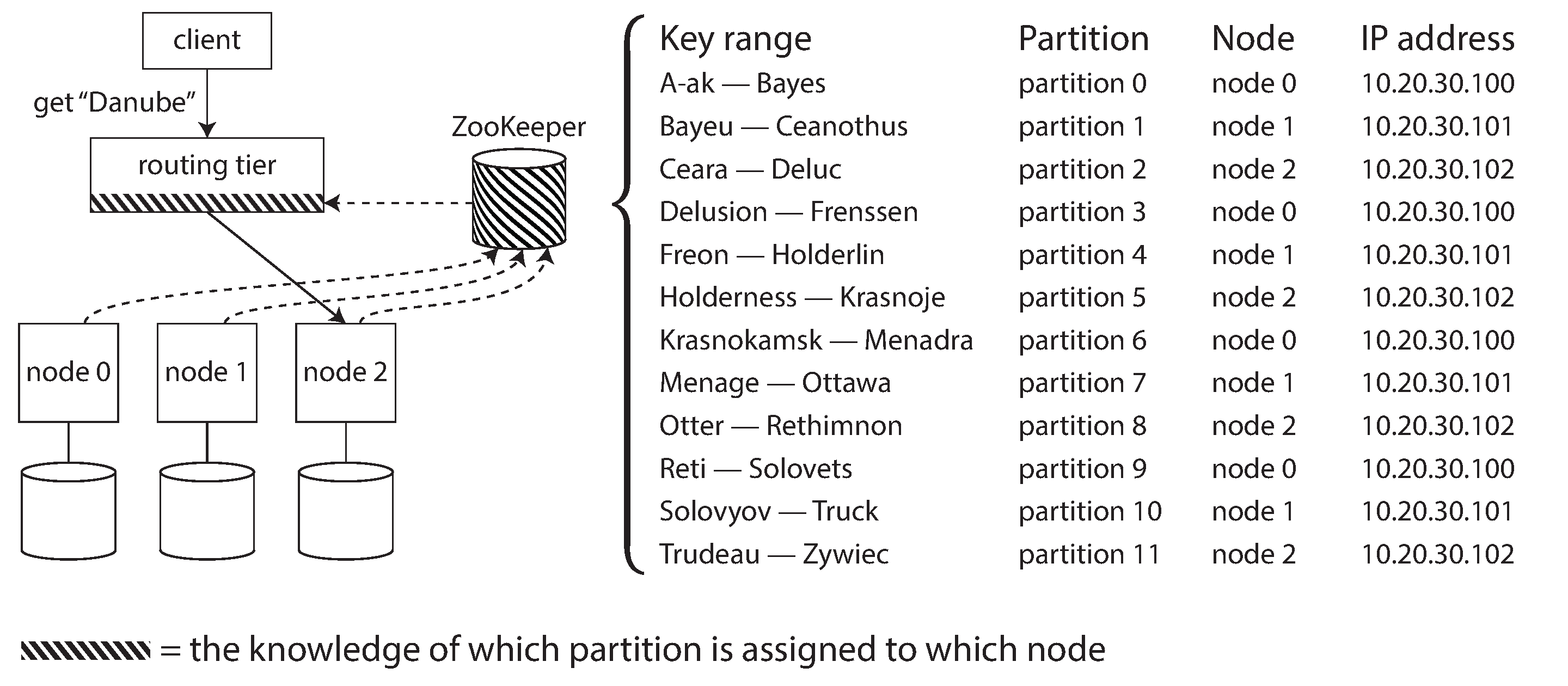
- LinkedIn’s Espresso uses Helix -> ZooKeeper
- HBase, SolrCloud, and Kafka also use ZooKeeper to track partition assignment.
- MongoDB's config server and mongos daemons
- Cassandra and Riak use gossip protocol
- Requests can be sent to any node, and that node forwards them to the appropriate node for the requested partition
- Puts more complexity in the database nodes but avoids the dependency on an external coordination service such as ZooKeeper
- Couchbase simplifies the design by not rebalancing automatically
- Use DNS to find IP of a node
Parallel Query Execution
- The massively parallel processing (MPP) query optimizer breaks this complex query into a number of execution stages and partitions, many of which can be executed in parallel on different nodes of the database cluster.
- Discuss more at [[DDIA-10 Batch Processing]]
- Previous: DDIA Chapter 5. Repliation
- Next: DDIA Chapter 7. Transactions