DDIA Chapter 5. Repliation
Buy the book https://dataintensive.net/
Intro
- Definition: Replication means keeping a copy of the same data on multiple machines that are connected via a network
- Why?
- closer to usert (latency)
- availability when some parts have failed
- increase read throughput
- All of the difficulty in replication lies in handling changes to replicated data
- Popular algorithms:single-leader, multi-leader, and leaderless replication.
- Trade-offs: sync/async, handle failed replicas
Leaders and Followers
- Definition: Each node that stores a copy of the database is called a replica
- Fundamental question: how do we ensure that all the data ends up on all the replicas?
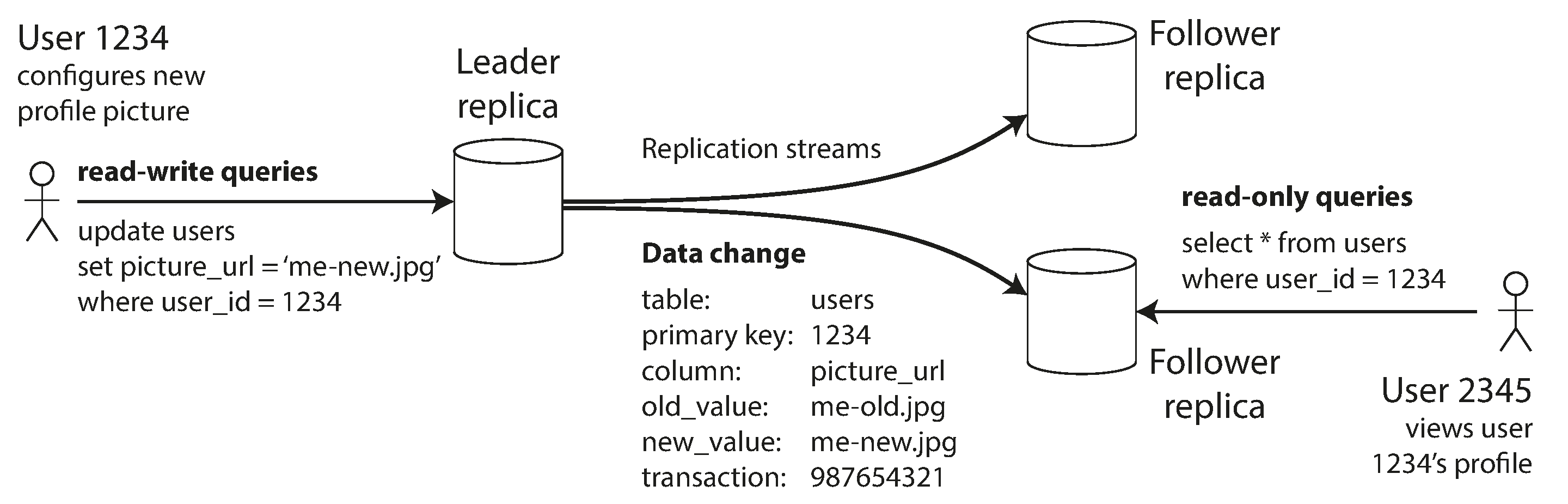
- Wide usages:
- Used in relational DBs PostgreSQL (since version 9.0), MySQL, Oracle Data Guard, and SQL Server’s AlwaysOn Availability Groups
- Used in some non-relational DBs MongoDB, RethinkDB, and Espresso
- distributed message brokers such as Kafka and RabbitMQ highly available queues also use it
Synchronous Versus Asynchronous Replication
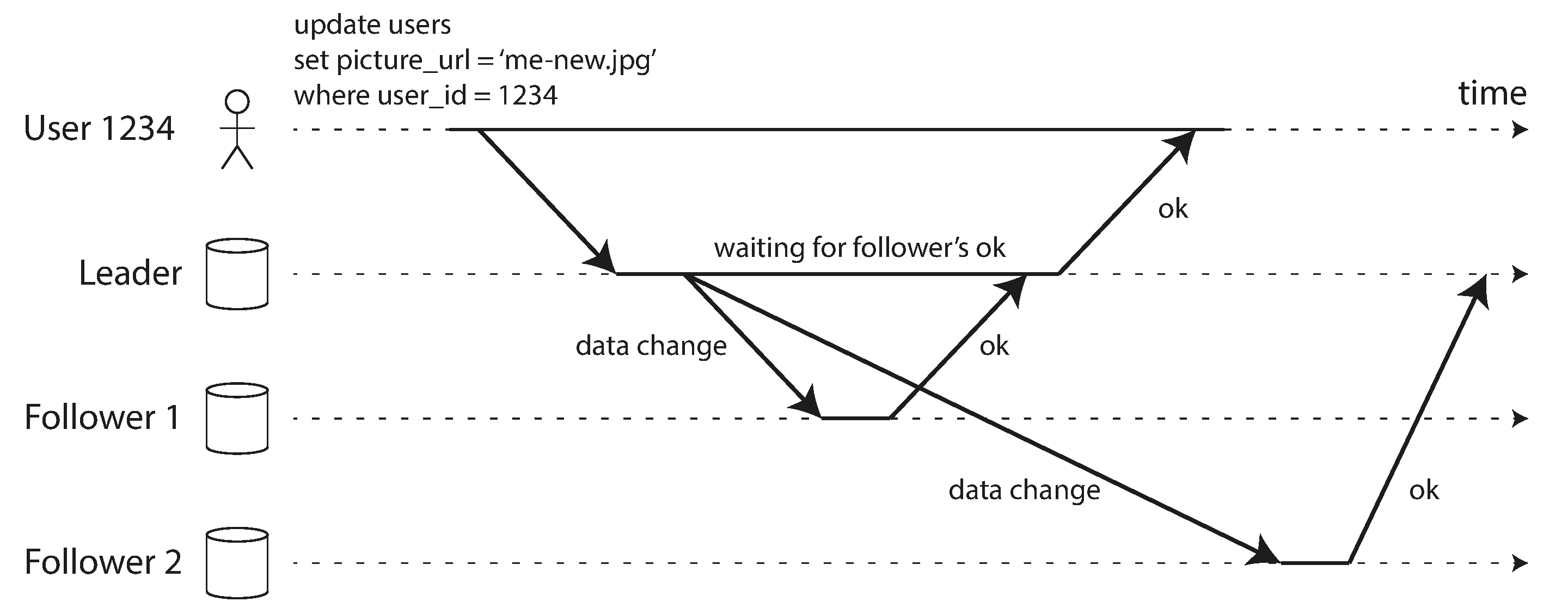
- Examples followers fall behind: if a follower is recovering from a failure, if the system is operating near maximum capacity, or if there are network problems between the nodes.
- Often, leader-based replication is configured to be completely asynchronous.
- In this case, if the leader fails and is not recoverable, any writes that have not yet been replicated to followers are lost.
- This means that a write is not guaranteed to be durable, even if it has been confirmed to the client.
- However, a fully asynchronous configuration has the advantage that the leader can continue processing writes, even if all of its followers have fallen behind.
- Weakening durability may sound like a bad trade-off, but asynchronous replication is nevertheless widely used, especially if there are many followers or if they are geographically distributed. More at [[#Problems with Replication Lag]]
- [[DDIA-9 Consistency and Consensus]] talks about consistency of replication and consensus
Setting Up New Followers
- Goal: to increase the number of replicas, or to replace failed nodes
- Question: ensure new follower has an accurate copy of leader data
- Process: snapshot copy, then requests data changes until caught up
Handling Node Outages
- Follower failure: Catch-up recovery
- Leader failure: Failover
Failover Process
- Determining that the leader has failed: timeout
- Choosing a new leader: election or appointed by previous controller node (more in [[DDIA-9 Consistency and Consensus]])
- Reconfiguring the system to use the new leader
- Discuss in [[DDIA-6 Partitioning#Request Routing]]
- The system needs to ensure that the old leader becomes a follower and recognizes the new leader.
Things can go wrong during failover:
- the new leader may not have received all the writes from the old leader before it failed
- Discarding writes is especially dangerous if other storage systems outside of the database need to be coordinated with the database contents (GitHub outage example)
- split brain two nodes both believe that they are the leader, be careful not shutdown both nodes
- Choosing right timeout
- More in [[DDIA-8 The Trouble with Distributed Systems]] and [[DDIA-9 Consistency and Consensus]]
Implementation of Replication Logs
Statement-based replication
Write-ahead log (WAL) shipping
- Storage engines usually write append log
- [[DDIA-3 Storage and Retrieval#SSTables and LSM-Trees]] log segments
- [[DDIA-3 Storage and Retrieval#B-Trees]] WAL before disk block
- Send same log to replicas
- Used in PostgreSQL, Oracle and others
- Disadvantage: low level database backward compatibility to allow zero-downtime upgrade
Logical (row-based) log replication
- Allows the replication log to be decoupled from the storage engine internals
- Also easier for external applications to parse
- Data warehouse offline analysis
- Custom indexes and caches
- [[DDIA-11 Stream Processing#Change Data Capture]]
Trigger-based replication
- Relational DB features: triggers and stored procedures.
- Triggers
- register custom application code ->
- automatically executed when a write transaction occurs ->
- log this change into a separate table ->
- read by an external process ->
- apply any necessary application logic and replicate the data change to another system.
- Examples: Databus for Oracle and Bucardo for Postgres
- Con: greater overheads, prone to bugs; Pro: flexible
Problems with Replication Lag
- Read-scaling architecture: create many followers, and distribute the read requests across those followers.
- Realistically work with asynchonous follower -> eventural consistency
Reading Your Own Writes
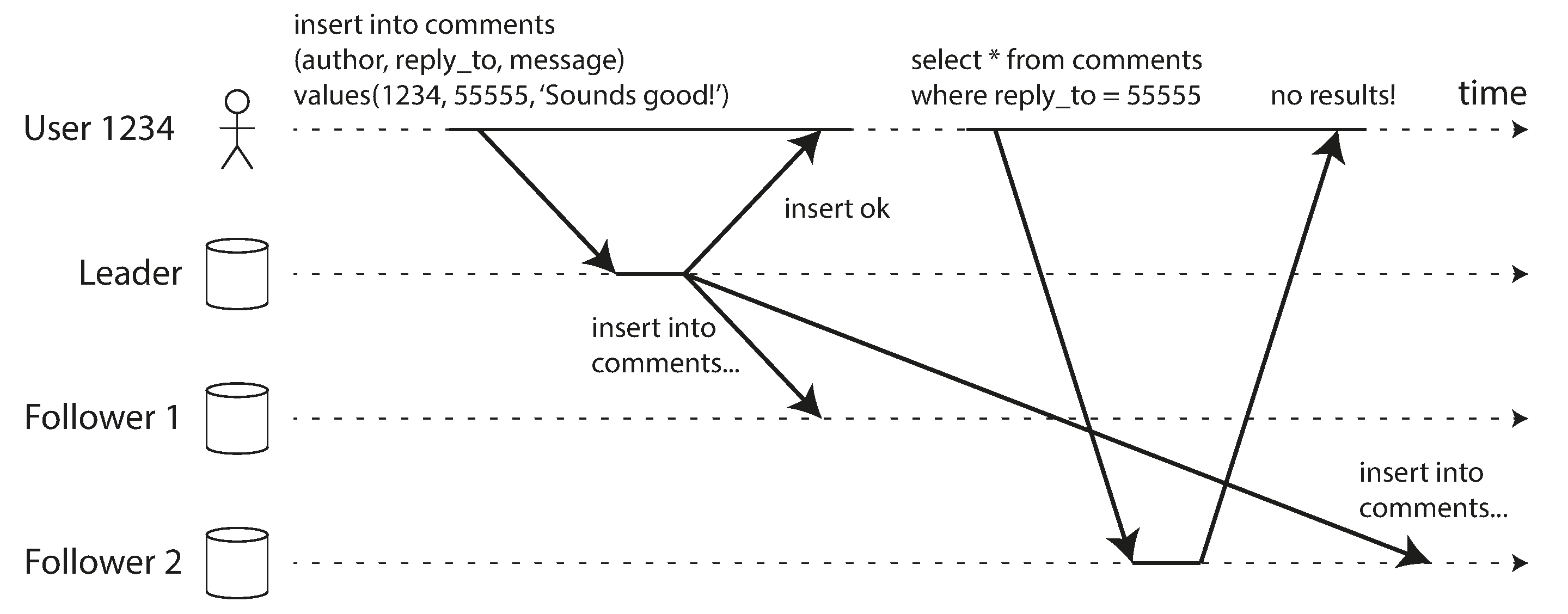
- Possible techniques
- read from leader for potentially modified data (e.g., user's own profile)
- track last update time make all reads from leader
- client remembers most recent write timestamp and system ensure proper replica
- multiple datacenter complexity
- cross-device read-after-write consistency
- metadata will need to be centralized
- may first need to route requests from all of a user’s devices to the same datacenter.
Monotonic Reads
- it’s possible for a user to see things moving backward in time.
- make sure that each user always makes their reads from the same replica
Consistent Prefix Reads
- Definition: If a sequence of writes happens in a certain order, then anyone reading those writes will see them appear in the same order.
- Distributed databases partitions don't have global ordering of writes
- One solution is to make sure that any writes that are causally related to each other are written to the same partition
- Algorithms that explicitly keep track of causal dependencies ([[#The “happens-before” relationship and concurrency]])
Solutions for Replication Lag
- Does the user experience need to avoid replication lag
- Ways the app to provide stronger guarantee
- Underlying database gaurantee by transactions
- Distributed database transactions are hard
- Discuss in [[DDIA-7 Transactions]] and [[DDIA-9 Consistency and Consensus]]
- Alternative mechanisms or Derived Data: Batch and Streaming
Multi-Leader Replication
- Definition
- Allow more than one node to accept writes
- Each node that processes a write must forward that data change to all the other nodes
- Each leader simultaneously acts as a follower to the other leaders
Use Cases for Multi-Leader Replication
Use on multi-datacenter deployment
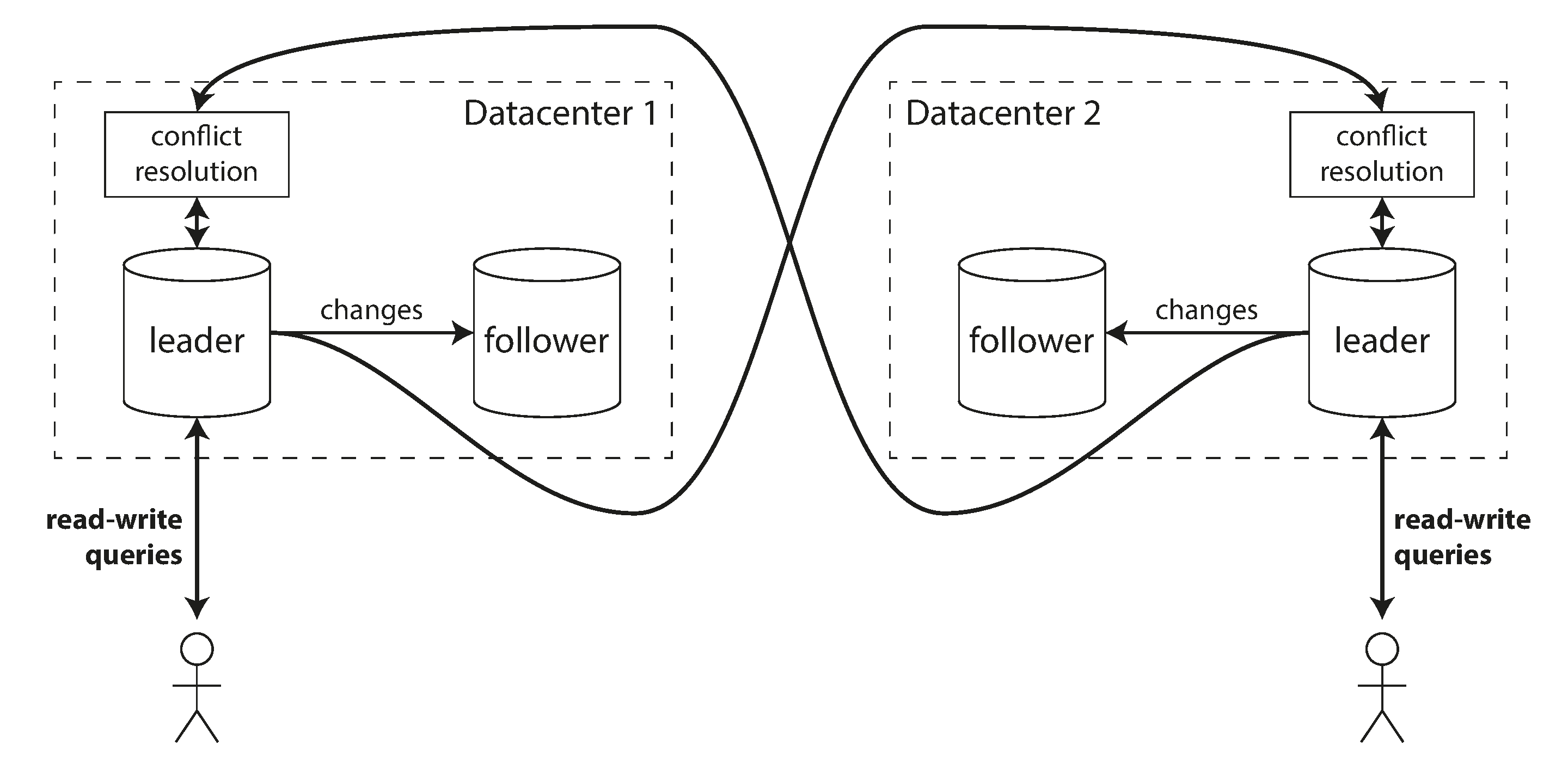
- Advantages of multi-leader configurations in multi-datacenter deployment:
- Performance
- Tolerance of datacenter outages
- Tolerance of network problems
- Downside
- Write conflicts (Discuss at [[#Handling Write Conflicts]])
- Dangerous from subtle configuration pitfalls and surprising interactions with other database features (https://scale-out-blog.blogspot.com/2012/04/if-you-must-deploy-multi-master.html)
Clients with offline operation
E.g., CouchDB is designed for this mode of operation
Collaborative editing
- automatic conflict resolution
- acquire lock before write, make unit of change very small
Handling Write Conflicts
Synchronous versus asynchronous conflict detection
- Need async conflict resolution, otherwise just use single-leader
Conflict avoidance
Converging toward a consistent state
- last write wins (LWW) more at [[#Detecting Concurrent Writes]] (implies data loss)
- Replica UUID and cetain replica take precedence over writes (implies data loss)
- Merge writes in certain way
- Record conflict explicitly and write app code that resolves later
Custom conflict resolution logic
- On write
- On read
- AUTOMATIC CONFLICT RESOLUTION
- Conflict-free replicated datatypes (CRDTs)
- Mergeable persistent data structures
- Operational transformation
Multi-Leader Replication Topologies
- A replication topology describes the communication paths along which writes are propagated from one node to another
- Most general: all-to-all
- More restricted MySQL default circular topology
- Start topology
- A problem with circular and star topologies is that if just one node fails, it can interrupt the flow of replication messages between other nodes, causing them to be unable to communicate until the node is fixed
- all-to-all can have issue of concurrent write, need version vectors discussed in [[#Detecting Concurrent Writes]]
- Be careful about multi-leader replication and check the database gaurantees
Leaderless Replication
- Riak, Cassandra, and Voldemort are open source datastores with leaderless replication models inspired by Dynamo
- Therefore also known as Dynamo-style
- In some leaderless implementations, the client directly sends its writes to several replicas
- while in others, a coordinator node does this on behalf of the client, that coordinator does not enforce a particular ordering of writes
Writing to the Database When a Node Is Down
- In leader-based configuration: failover
- In a leaderless configuration: read requests are also sent to several nodes in parallel
- Version numbers are used to determine which value is newer
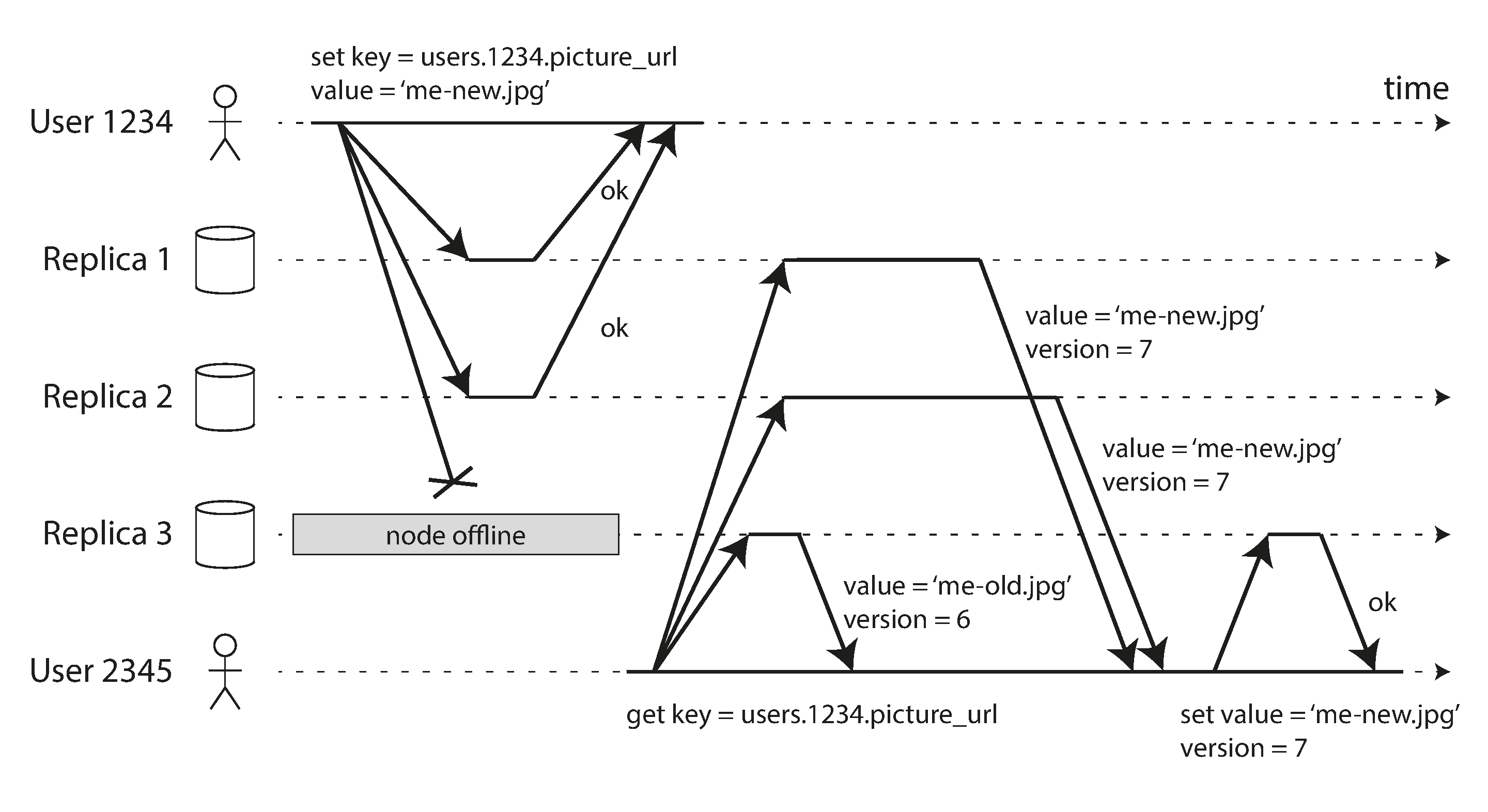
Read repair and anti-entropy
- To make stale value notes catch up
- Read repair: client writes newer value back to stale replica
- Anti-entropy process: background process taht constantly looks for differences, without it rarely read may be missing from some replicas
Quorums for reading and writing
- If there are n replicas
- every write must be confirmed by w nodes to be considered successful
- must query at least r nodes for each read.
- As long as w + r > n, we expect to get an up-to-date value when reading
- n, w, r are typically configurable
- There may be more than n notes in the cluster to allow partinioning
- If fewer than the required w or r nodes are available, writes or reads return an error.
Limitations of Quorum Consistency
However, even with w + r > n, there are likely to be edge cases where stale values are returned:
- if a sloppy quorum is used
- two writes occur concurrently: one safe solutuon is to merge writes
- write happens concurrently with a read
- a write cucceeded on some replicas but failed overall
- node carrying new value fails and restored from a replica carrying old value
- edge cases from timing (see in [[DDIA-9 Consistency and Consensus#Linearizability and quorums]])
Thus:
- Dynamo-style databases are generally optimized for use cases that can tolerate eventual consistency.
- The parameters w and r allow you to adjust the probability of stale values being read
- Stronger gaurantees require transactions or consensus: [DDIA-7 Transactions]] and [[DDIA-9 Consistency and Consensus]]
Monitoring staleness
- Possible in leader-based replication
- writes are applied to the leader and to followers in the same order, and each node has a position in the replication log
- Subtract a follower's current position from leader's current position
- No fixed write order in leaderless-based replication
- Also no staleness limit in read-repair-only database
Sloppy Quorums and Hinted Handoff
- Leaderless high availability and low latency:
- appropriately configured quorums can tolerate the failure of individual nodes without the need for failover
- can also tolerate individual nodes going slow
- But not very fault-tolerant when large numbers of nodes are cut off
- Trade-offs:
- error all requests when quorum is not reached
- accept writes to some reachable nodes (sloppy quorum)
- hinted handoff: Once the network interruption is fixed, any writes that one node temporarily accepted on behalf of another node are sent to the appropriate "home" nodes.
- Increase write availability: as long as any w nodes are available, the database can accept writes
- There is no guarantee that a read of r nodes will see it until the hinted handoff has completed.
- Optional in all Dynamo implementations; default in Riak; disabled by default in Cassandra and Voldemort
Multi-datacenter operation
- Cross-DC replication as a use case for [[#Multi-Leader Replication]]
- Leaderless is also suitable: designed to tolerate conflicting concurrent writes, network interruptions, and latency spikes.
- Examples
- Cassandra and Voldemort: n includes nodes in all DCs, write send to all replicas, client only waits for ack from same DC, higher latency cross-DC writes are background async
- Riak: n within on DC
Detecting Concurrent Writes
- Dynamo-style DBs allow concurrent write to the same key
- Similar to multi-leader replication ([[#Handling Write Conflicts]])
- Dynamo-style also has conflicts during read repair or hinted handoff
- Fundamental problem is that events may arrive in a different order at different nodes, due to variable network delays and partial failures
- Goal: achieve eventual consistency
- Poor implementaions: app developer needs to know DB conflict handling internals
Explore more details about [[#Handling Write Conflicts]] below:
Last write wins (discarding concurrent writes)
- writes are concurrent -> order is undefined
- Force arbitrary order: use timestamp
- Pick largest timestamp (last write wins (LWW)) is the only supported method in Cassandra, and optional feature in Riak
- LWW cost is durability: only one write suvives
- May drop non-concurrent writes because [[DDIA-8 The Trouble with Distributed Systems#Timestamps for ordering events]]
- Only safe way of using LWW is to ensure unique key ([[202112252056 Cassandra does not need vector clocks]])
The “happens-before” relationship and concurrency
- concurrent means both operations do not know each other
- if not concurrent, later operation can overwrite prior
- otherwise needs conflict resolution
Capturing the happens-before relationship
Note that the server can determine whether two operations are concurrent by looking at the version numbers—it does not need to interpret the value itself (so the value could be any data structure). The algorithm works as follows:
- The server maintains a version number for every key, increments the version number every time that key is written, and stores the new version number along with the value written.
- When a client reads a key, the server returns all values that have not been overwritten, as well as the latest version number. A client must read a key before writing.
- When a client writes a key, it must include the version number from the prior read, and it must merge together all values that it received in the prior read. (The response from a write request can be like a read, returning all current values, which allows us to chain several writes like in the shopping cart example.)
- When the server receives a write with a particular version number, it can overwrite all values with that version number or below (since it knows that they have been merged into the new value), but it must keep all values with a higher version number (because those values are concurrent with the incoming write).
Merging concurrently written values
- If several operations happen concurrently, clients have to clean up afterward by merging the concurrently written values. Riak calls these concurrent values siblings.
- Merging sibling values == conflict resolution in multi-leader
- Mark tombstone when removal (previously seen at [[DDIA-3 Storage and Retrieval#Hash Indexes]])
- Riak supports CRDTs
Version vectors
- Single version number is not sufficient when there are multiple replicas accepting writes concurrently
- Use a version number per replica as well as per key
- Each replica increments its own version number when processing a write, and also keeps track of the version numbers it has seen from each of the other replicas
- The collection of version numbers from all the replicas is called a version vector, it allows database to distinguish between overwrites and concurrent writes
- Previous: Book Review: Atomic Habits
- Next: DDIA Chapter 6. Partitioning