DDIA Chapter 9. Consistency and Consensus
Buy the book https://dataintensive.net/
The main idea of this chapter is:
- How to build fault-tolerant distributed systems?
- Find the general-purpose abstraction with useful guarantees that applications can rely on.
- Consensus: getting all of the nodes to agree on something.
- reliably reaching consensus in spite of network faults and process failures is a surprisingly tricky problem
- applications can use consensus for many things
- Need to understand the scope of what can and cannot be done.
Consistency Guarantees
- [[DDIA-5 Replication#Problems with Replication Lag]] mentioned eventual consistency but is weak guarantee. Bugs are surfaced when there's high concurrency or system faults.
- Systems with stronger guarantees may have worse performance or be less fault-tolerant than systems with weaker guarantees.
- Distributed consistency models and the transaction isolation levels ([[DDIA-7 Transactions#Weak Isolation Levels]]) have overlap but mostly independent concerns.
- Transaction isolation avoids race conditions due to concurrent execution
- Distributed consistency coordinates replicas' states
The deeply linked topics this chapter discusses:
- [[#Linearizability]]: the strongest consistency model
- [[#Ordering Guarantees]]: causality and total ordering issue in ordering events
- [[#Distributed Transactions and Consensus]] the solution to atomically commit a distributed transaction
Linearizability
- The idea: database fakes to only have one replica, and all operations on it are atomic.
- It is called linearizability also known as atomic consistency, strong consistency, immediate consistency, or external consistency.
- Guarantee reads most recent value -> a recency guarantee
What Makes a System Linearizable?
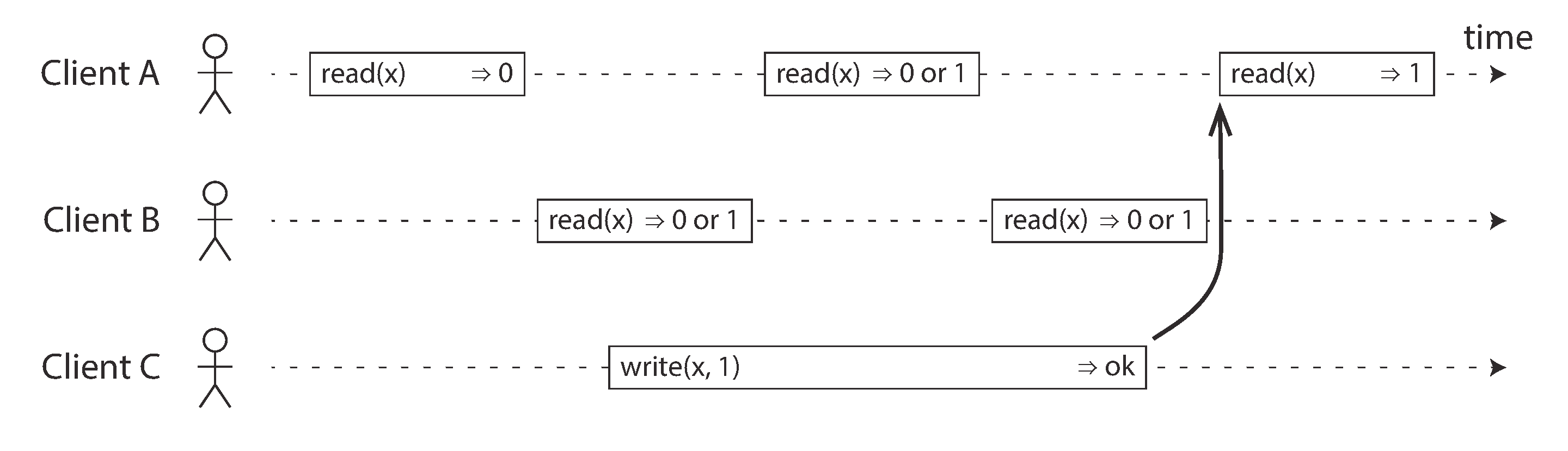
- When clients reading the same object
x, called register or a key in a KV store, the concurrent reads return either old or new value - Insufficient: reads concurrent to writes can see a value flip
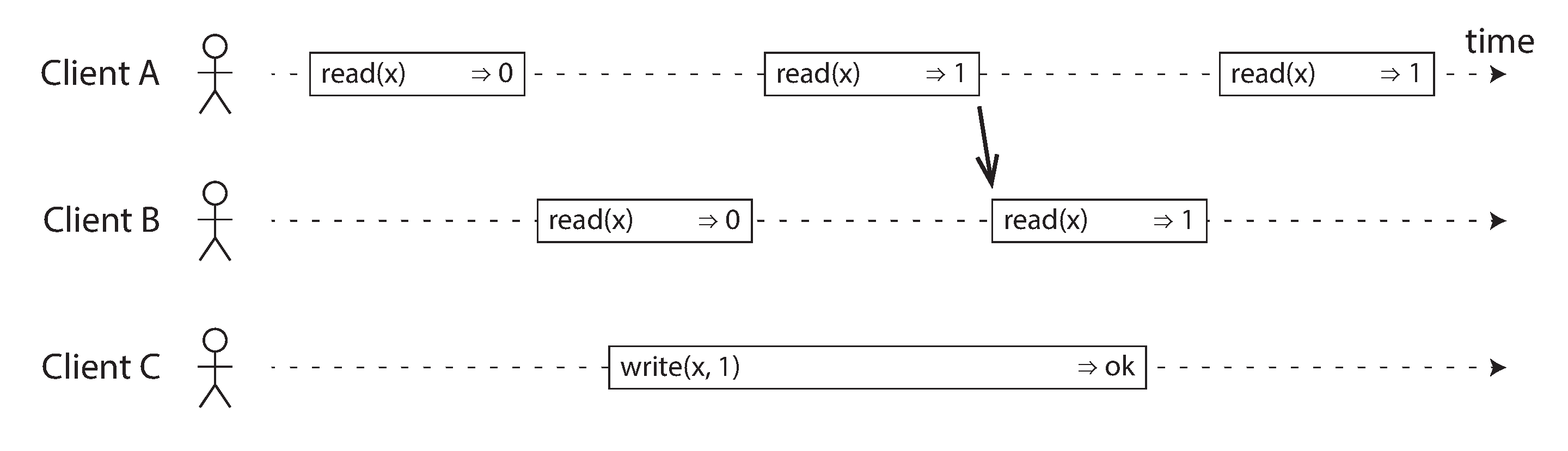
- Added one more constraint that subsequent reads must also return the new value
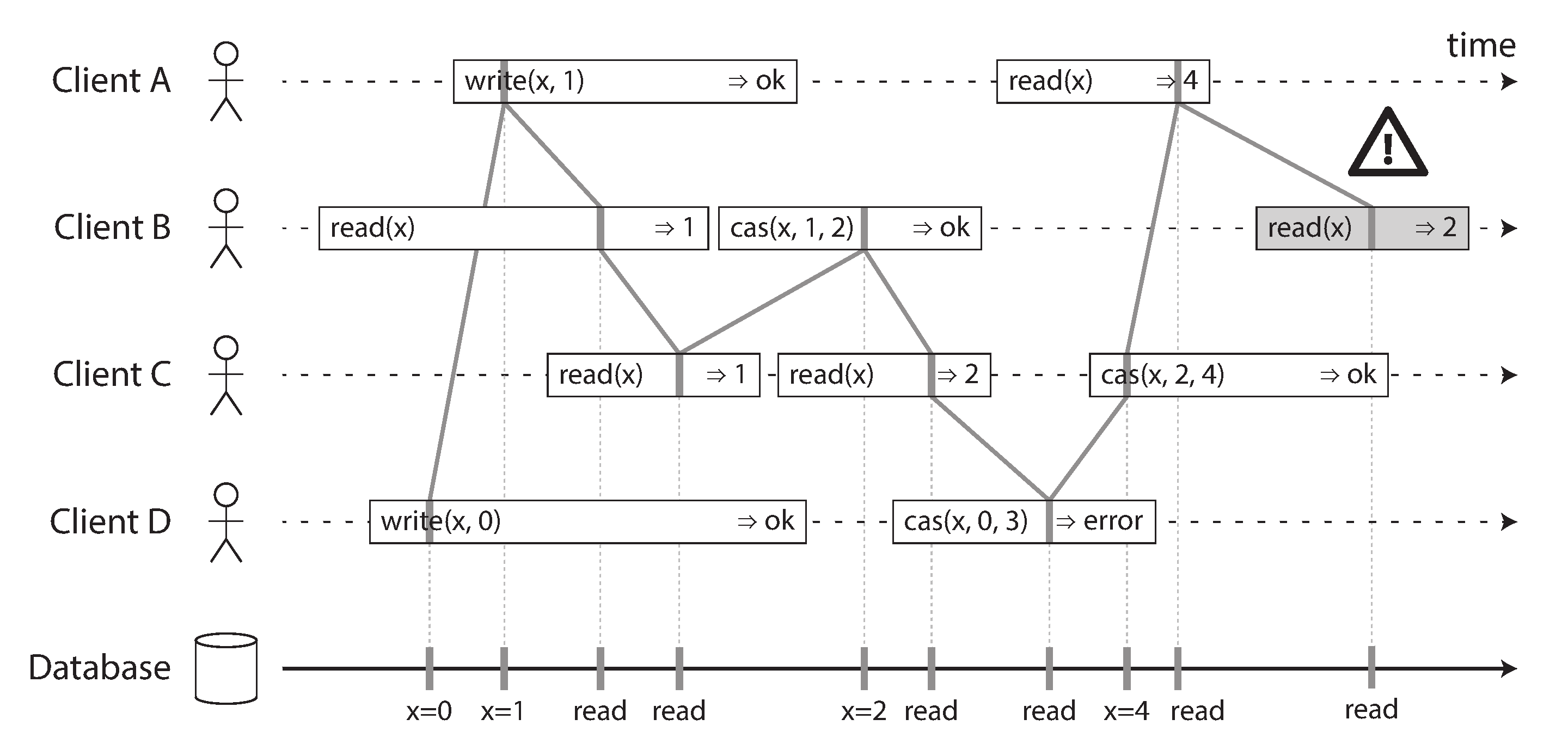
- In above picture, we add a new type of operation
cas(see [[DDIA-7 Transactions#Compare-and-set]]) - Notice the final read by client B (in a shaded bar) is not linearizable, client A has already read the new value 4 before B’s read started.
- Formal definition: Linearizability: A Correctness Condition for Concurrent Objects
- It is possible but expensive to test linearizability by recording the timings of all requests and responses and check whether they can be arranged into a valid sequential order.
Linearizability VS Serializability?
- Linearizability is a recency guarantee of an individual object
- It doesn't group operations into transactions so it can't prevent problems like [[DDIA-7 Transactions#Write Skew and Phantoms]] unless [[DDIA-7 Transactions#Materializing conflicts]].
- Database provide both serialization and linearizability is called strict serializability or strong one-copy serializability (strong-1SR)
- [[DDIA-7 Transactions#Two-Phase Locking 2PL]] and [[DDIA-7 Transactions#Actual Serial Execution]] are typically linearizable.
- [[DDIA-7 Transactions#Serializable Snapshot Isolation SSI]] is not linearizable.
Relying on Linearizability
Let's talk about few examples that linearizability is a requirement.
Locking and leader election
One way of electing a leader is to use a lock: every node that starts up tries to acquire the lock, and the one that succeeds becomes the leader. The acquiring lock must be linearizable.
Apache ZooKeeper and etcd can be used to implement distributed locks and leader election.
- They use consensus algorithms ([[#Fault-Tolerant Consensus]])
- A linearizable storage service is the basic foundation for these coordination tasks
- Distributed locking is also used at more granular level, e.g., Oracle Real Application Clusters lock per disk page
Strictly speaking, ZooKeeper and etcd provide linearizable writes, but reads may be stale, since by default they can be served by any one of the replicas. You can optionally request a linearizable read: etcd calls this a quorum read, and in ZooKeeper you need to call
sync()before the read
Constraints and uniqueness guarantees
Examples
- Enforce unique username, one of concurrent writer is returned an error. (Acquiring a lock for the writing item)
- Bank balance never negative, booking same seat. (Single up-to-date value that all nodes agree on)
Comparing to relational databases:
- Uniqueness constraint requires linearizability
- Foreign key or attribute constraints can be implemented without requiring linearizability (Coordination-Avoiding Database Systems)
Cross-channel timing dependencies
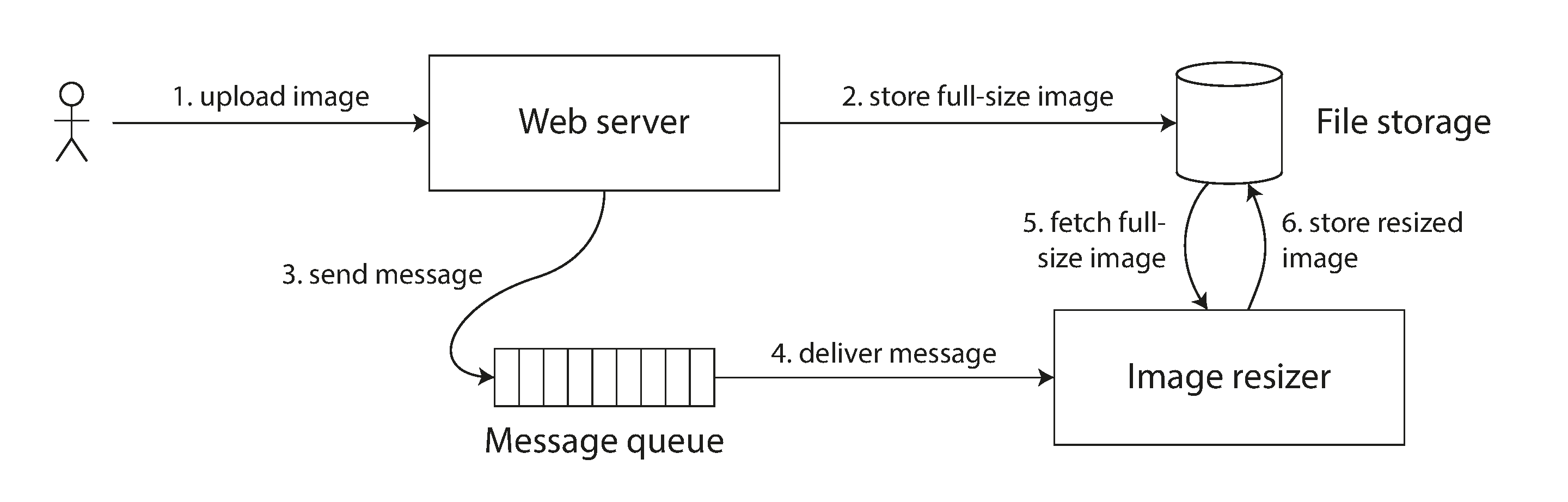
- In above example, if the file storage service is not linearizable, there is the risk of a race condition of message queue is faster than the storage service replication lag.
- The key here is two different communication channels: file storage and message queue.
- Linearizability is the simplest to understand.
- Additional approaches has complexity cost ([[DDIA-5 Replication#Reading Your Own Writes]]).
Implementing Linearizable Systems
How to implement linearizability (behave like a single copy of data), and tolerate faults (by holding more than one copy of data)?
Single-leader replication (potentially linearizable)
- If you make reads from the leader, or from synchronously updated followers, they have the potential to be linearizable
- Cross partition transactions linearizability is hard ([[#Distributed Transactions and Consensus]])
- If it uses snapshot isolation, it is not linearizable.
- Linearizability is violated when delusional leader continue to serve requests or failover lose committed writes ([[DDIA-5 Replication#Handling Node Outages]])
Consensus algorithms (linearizable)
- Resemble single-leader replication, but consensus protocols prevent split-brain and stale-replicas.
- ZooKeeper and etcd leverage consensus to implement safe linearizable storage.
Multi-leader replication (not linearizable)
- Concurrent processing writes on multiple nodes and asynchronous replication needs [[DDIA-5 Replication#Handling Write Conflicts]].
Leaderless replication (probably not linearizable)
- Dynamo-style [[DDIA-5 Replication#Leaderless Replication]]
- LWW conflict resolution methods base on time-of-day clocks, and is nonlinearizable due to clock skew
- Sloppy quorums ([[DDIA-5 Replication#Sloppy Quorums and Hinted Handoff]]) is nonlinearizable.
- Strict quorums can possibly be nonlinearizable.
Linearizability and quorums
Example race conditions in Dynamo-style strict quorum.
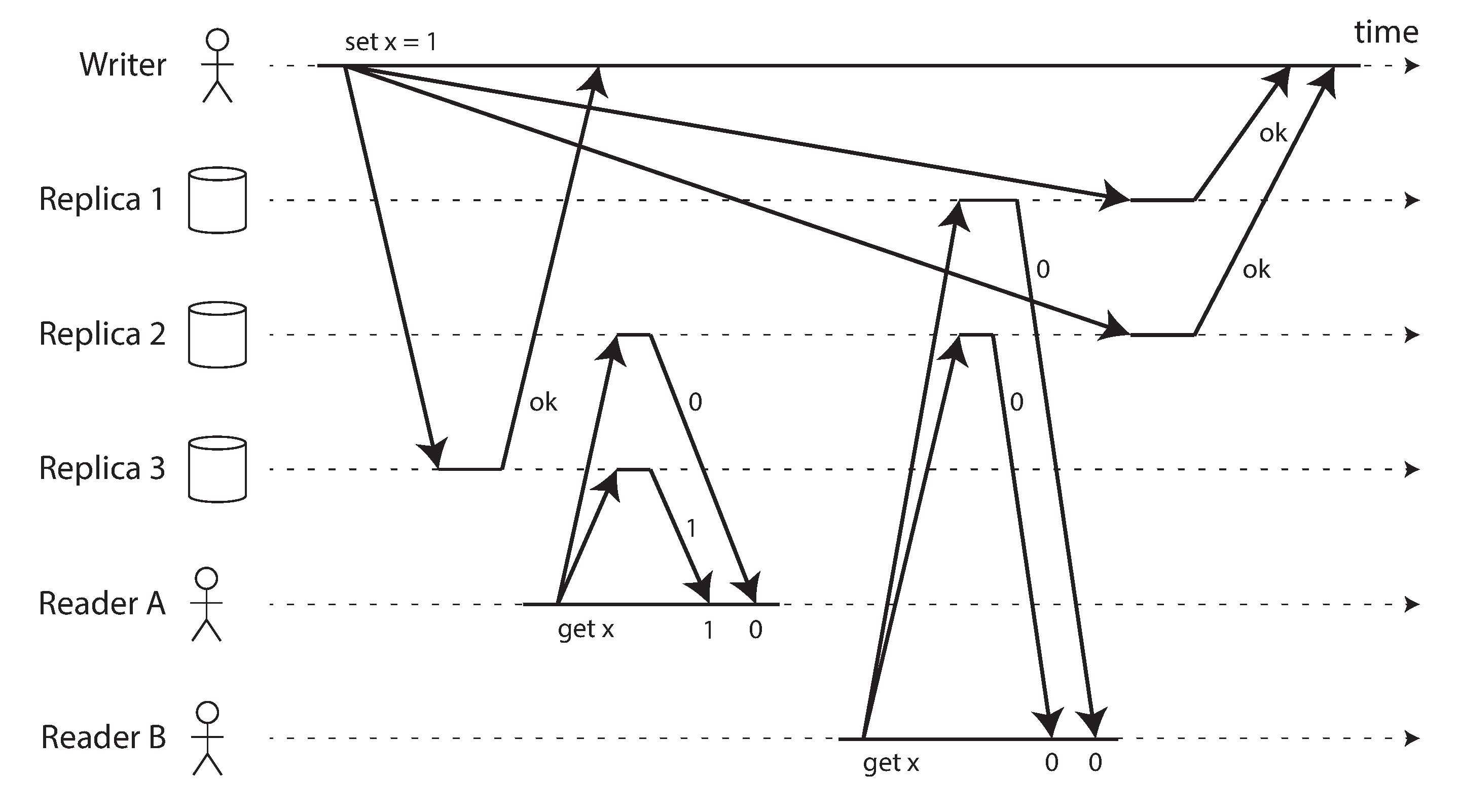
- n=3, w=3, r=2, quorum condition is met
- B and A do not have linearizability guarantee
- It is possible to make Dynamo-style quorums linearizable at the cost of reduced performance
- reader performs read repair ([[DDIA-5 Replication#Read repair and anti-entropy]])
- writer reads the latest state of a quorum of nodes
- but LWW will still lose linearizability during multiple concurrent writes
- Linearizable compare-and-set requires consensus algorithm, cannot be implemented this way
- It is safest to assume that a leaderless system with Dynamo-style replication does not provide linearizability.
The Cost of Linearizability
The CAP theorem
- If your application requires linearizability, and some replicas are disconnected from the other replicas due to a network problem, then some replicas cannot process requests while they are disconnected: they must either wait until the network problem is fixed, or return an error (either way, they become unavailable).
- If your application does not require linearizability, then it can be written in a way that each replica can process requests independently, even if it is disconnected from other replicas (e.g., multi-leader). In this case, the application can remain available in the face of a network problem, but its behavior is not linearizable.
The Unhelpful CAP Theorem
- Partition tolerance / network fault is not a choice
- Better framed as either Consistent or Available when Partitioned
- Many highly available systems do not meet CAP's definition.
- Best avoid CAP due to these misunderstanding and confusion.
CAP only considers network partition, it does not consider network delays, dead nodes, or other trade-offs. There're many more impossibility results in distributed systems: A Hundred Impossibility Proofs for Distributed Computing (1988)
CAP has now been superseded by more precise results:
- Limitations of Highly-Available Eventually-Consistent Data Stores (2015): An eventually consistent data store implementing multi-valued registers (MVR) cannot satisfy a consistency model strictly stronger than observable causal consistency (OCC).
- Consistency, Availability, and Convergence (2011): No consistency stronger than Real Time Causal Consistency (RTC) can be provided in an always-available one-way convergent system.
Linearizability and network delays
The reason for dropping linearizability is performance, not fault tolerance. Sequential Consistency Versus Linearizability (1994) proves that response time of read and write requests is at least proportional to the uncertainty of delays in the network, if you want linearizability.
Ordering Guarantees
Ordering is an important fundamental idea:
- [[DDIA-5 Replication]] the main purpose of the leader in the single-leader replication is to determine order of writes
- [[DDIA-7 Transactions]] transaction is about execute in some sequential order
- [[DDIA-8 The Trouble with Distributed Systems#Relying on Synchronized Clocks]] clock determines write order
Ordering and Causality
- causality: what happened before what
- If a system obeys the ordering imposed by causality, we say that it is causally consistent
- snapshot isolation provides causal consistency
The causal order is not a total order
- A total order allows any two elements to be compared. It is a mathematical concept.
- partially ordered: in some cases one set is greater than another
- In a linearizable system, we have a total order of operations
- Causality defines a partial order
- There are no concurrent operations in a linearizable datastore
Linearizability is stronger than causal consistency
- Linearizability implies causality
- Linearizability can harm performance and availability
- Causal consistency is the strongest possible consistency model that does not slow down due to network delays, and remains available
- In many cases, systems that appear to require linearizability in fact only really require causal consistency
- Recent researches
- Challenges
Capturing causal dependencies
Key ideas are:
- When a replica processes an operation, it must ensure that all causally preceding operations have been processed, otherwise wait
- Version vectors can be generalized to track causal dependencies across the entire database, not just a single key (in [[DDIA-5 Replication#Detecting Concurrent Writes]])
Sequence Number Ordering
- Explicitly tracking all the data that has been read would mean a large overhead.
- Solution: use sequence numbers or timestamps to order events
- Compact and provides a total order
- Can be created as consistent with causality
- Concurrent operations may be ordered arbitrarily
- Single-leader can assign a counter to replication log.
Noncausal sequence number generators
Multi-leader and leaderless databases cannot generate sequence numbers that are causal consistent.
In practice, these methods can generate sequence numbers for operations:
- Each node can generate its own independent set of sequence numbers
- Attach a timestamp from a time-of-day clock to each operation. They might be sufficient to total ordered operations if having sufficient resolution
- Preallocate blocks of sequence numbers.
These are more performance than a single node, but notice the sequence numbers they generate are not consistent with causality.
Note that it is possible to make physical clock timestamps consistent with causality:
in [[DDIA-8 The Trouble with Distributed Systems#Synchronized clocks for global snapshots]] we discussed Google’s Spanner, which estimates the expected clock skew and waits out the uncertainty interval before committing a write.
This method ensures that a causally later transaction is given a greater timestamp.
Lamport timestamps
Leslie Lamport: "Time, Clocks, and the Ordering of Events in a Distributed System (1978)" is the most cited paper in the field of distributed systems. Lamport timestamp is a simple method for generating causally consistent sequence numbers.
It works like this:
- The Lamport timestamp is simply a pair of
(counter, nodeID). - First compare counter
- If timestamp equal, the one with greater node ID is the greater timestamp
- (Key idea starts here)
- Every node and every client keeps track of the maximum counter value it has seen so far, and includes that maximum on every request
- When a node receives a request or response with a maximum counter value greater than its own counter value, it immediately increases its own counter to that maximum.

Notice when client A writes max=1 to node 2, it receives (5, 2) timestamp, the next write to node 1 increases node 2 counter to 6.
What ensures the ordering is that every causal dependency results in an increased timestamp.
Difference between Lamport timestamp and [[DDIA-5 Replication#Version vectors]]:
- They have different purposes
- Version vectors can distinguish whether two operations are concurrent or whether one is causally dependent on the other
- Lamport timestamps always enforce a total ordering
- From the total ordering of Lamport timestamps, you cannot tell whether two operations are concurrent or whether they are causally dependent.
- Lamport timestamps are more compact.
Timestamp ordering is not sufficient
- The total order of operations only emerges after you have collected all of the operations.
- In order to implement something like a uniqueness constraint for usernames, it’s not sufficient to have a total ordering of operations.
- You also need to know when that order is finalized (discuss next in [[#Total Order Broadcast]]).
Total Order Broadcast
How to scale the throughput beyond single leader and handle failover?
Required safety properties:
- Reliable delivery: No messages are lost, retry until network is eventually repaired
- Totally ordered delivery: Messages are delivered to every node in the same order
Using total order broadcast
- There's a connection between total order broadcast and consensus
- State machine replication principle (Implementing Fault-Tolerant Services Using the State Machine Approach: A Tutorial): total order broadcast helps replica stay consistent with each other
- Implement serializable transactions
- Order is fixed at the time the messages are delivered, it is a way of creating a log
- Implement lock service: the sequence number can serve as a fencing token (
zxidin ZooKeeper).
Implementing linearizable storage using total order broadcast
Close links between linearizability and total order broadcast:
In a formal sense, a linearizable read-write register is an “easier” problem. Total order broadcast is equivalent to consensus, which has no deterministic solution in the asynchronous crash-stop model, whereas a linearizable read-write register can be implemented in the same system model.
However, supporting atomic operations such as compare-and-set or increment-and-get in a register makes it equivalent to consensus. Thus, the problems of consensus and a linearizable register are closely related.
Implement linearizable compare-and-set operation by using total order broadcast as an append-only log:
-
Append a message to the log, tentatively indicating the new value you want to claim.
-
Read the log, and wait for the message you appended to be delivered back to you. (If you don't wait, it will be neither linearizable nor sequentially consistent)
-
Check for any messages claiming the new value that you want. Commit the claim and acknowledge it to the client, or abort the operation.
Above procedure provides sequential consistency / timeline consistency, which is a weaker guarantee than linearizability. To further ensure reads linearizability in addition to the writes, options are:
- Sequence reads through the log by appending a message, reading the log, and performing the actual read when the message is delivered back to you. (Quorum reads in etcd)
- If the log allows you to fetch the position of the latest log message in a linearizable way, you can query that position, wait for all entries up to that position to be delivered to you, and then perform the read. (ZooKeeper
sync()operation) - Read from synchronously updated replica. (Chain Replication for Supporting High Throughput and Availability)
Implementing total order broadcast using linearizable storage
The inverse of building linearizable compare-and-set operation from total order broadcast.
- Assumption: you have a linearizable register that stores an integer and that has an atomic increment-and-get (or compare-and-set) operation.
- Then: for every message you want to send through total order broadcast, you increment-and-get the linearizable integer, and then attach the value you got from the register as a sequence number to the message.
- Then: send the message to all nodes (resending any lost messages)
- The recipients will deliver the messages consecutively by sequence number.
The key difference between total order broadcast and timestamp ordering is that total order broadcast has no sequence gaps.
In fact, linearizable compare-and-set (or increment-and-get) register and total order broadcast are both equivalent to consensus.
Distributed Transactions and Consensus
The simple yet fundamental goal: get several nodes to agree on something.
[[DDIA-5 Replication]], [[DDIA-7 Transactions]], system models ([[DDIA-8 The Trouble with Distributed Systems]]), [[#Linearizability]] and [[#Total Order Broadcast]] are prerequisite knowledge to tackle the consensus problem.
What are situations in which consensus is required?
- Leader election: leadership position will become contested during network fault, split-brain situation will result in inconsistency and data loss.
- Atomic commit: a transaction may fail on some nodes but succeed on others, they need to either all abort/roll back, or they all commit. Also known as atomic commit problem.
The algorithms for consensus:
- two-phase commit (2PC) algorithm is a kind, but not a very good one.
- ZooKeeper (Zab) and etcd (Raft) are better ones.
Atomic Commit and Two-Phase Commit (2PC)
From single-node to distributed atomic commit
When multiple nodes are involved in a transaction?
- Multi-object transaction in a partitioned database
- Term-partitioned secondary index entries may be on a different node from the primary data
Rules:
- A transaction commit must be irrevocable. (Although compensating transaction is allowed.)
- A node must only commit once it is certain that all other nodes in the transaction are also going to commit.
Introduction to two-phase commit
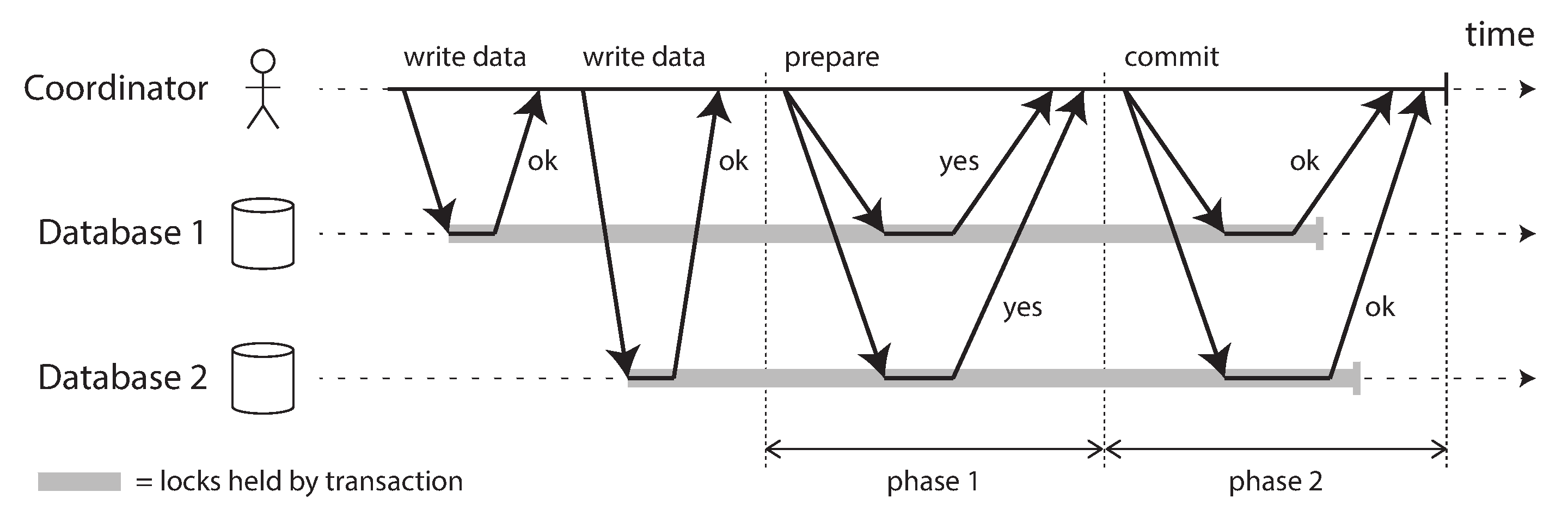
- The coordinator is often implemented as a library within the same application process that is requesting the transaction, but it can also be a separate process or service.
- Prepare phase and commit phase.
A system of promises
Two crucial "points of no return" that ensure the atomicity:
- when a participant votes "yes", it promises that it will definitely be able to commit later
- once the coordinator decides, that decision is irrevocable.
The coordinator retries indefinitely for the commit phase until it hears back from all the participants. The participant node, if crashed, should recover and commit.
Coordinator failure
If the coordinator crashes or the network fails at this point, the participant can do nothing but wait (in doubt or uncertain).
In principle, the participants could communicate among themselves to find out how each participant voted and come to some agreement, but that is not part of the 2PC protocol.
The coordinator must recover from reading the transaction log. Notice this is a blocking protocol.
Distributed Transactions in Practice
2PC is very slow, in MySQL it's 10x slower (Distributed Transactions in MySQL (2013)).
Much of the performance cost inherent in two-phase commit is due to the additional disk forcing (fsync) that is required for crash recovery, and the additional network round-trips.
Cloud vendors like Azure does not provide distributed transactions:
- Transactions in Windows Azure (with Service Bus) – An Email Discussion
- Understanding Transactions in Azure
What we mean by "distributed transactions"?
- Database-internal distributed transactions: some distributed databases support it
- Heterogeneous distributed transactions: a lot more challenging, but useful!
One example of heterogeneous distributed transaction use case is exactly-once message processing (message delivery + database writes).
XA transactions
X/Open XA (short for eXtended Architecture) is a standard for implementing two-phase commit across heterogeneous technologies. Widely supported by relational databases and message brokers.
XA assumes that your application uses a network driver or client library to communicate with the participant databases or messaging services. The library is responsible for participants tracking, crash recovery and communication with the database server.
Holding locks while in doubt
The lock will prevent any write or potentially read to the data. If coordinator does not recover, the lock will block other transactions forever.
Recovering from coordinator failure
If orphaned in-doubt transactions occur, the only way out is admin manually decide whether to commit or roll back each in-doubt transactions. XA implementations usually have emergency escape hatch to allow a participant to unilaterally decide to abort or commit an in-doubt transaction without a definitive decision from the coordinator.
Limitations of distributed transactions
- Coordinator is SPOF
- Coordinator makes application servers no longer stateless
- XA does not work with several things across data systems
- Even for internal distributed transactions that have less constraints, 2PC amplifying failures is against fault-tolerance.
[[DDIA-11 Stream Processing]] talks about alternatives to achieve heterogeneous distributed transactions.
Fault-Tolerant Consensus
- Informal definition: getting several nodes to agree on something.
- Formal definition: one or more nodes may propose values, and the consensus algorithm decides on one of those values.
The consensus algorithm must satisfy properties: uniform agreement, integrity, validity, termination.
- uniform agreement and integrity define the core idea
- validity rules out trivial solutions
- termination formalizes the idea of fault tolerance. A consensus algorithm must make progress, comparing to 2PL where in-doubt participants can stuck.
Notes on termination:
- In this system model (crashed node disappears and never comes back), any algorithm that has to wait for a node to recover is not going to be able to satisfy the termination property. In particular, 2PC does not meet the requirements for termination.
- Any consensus algorithm requires at least a majority of nodes to be functioning correctly in order to assure termination (proved).
- Majority safely forms a quorum ([[DDIA-5 Replication#Quorums for reading and writing]]).
- Most consensus algorithms ensure safety properties are always met, therefore large scale outages cannot cause invalid decisions although processing requests are blocked.
- Most consensus algorithms assume that there are no Byzantine faults, which may break safety properties.
Consensus algorithms and total order broadcast
Best-known fault-tolerant consensus algorithms: Viewstamped Replication (VSR), Paxos, Raft, and Zab.
They decide on a sequence of values, in other words total order broadcast. This is equivalent to performing several rounds of consensus.
Single-leader replication and consensus
Why [[DDIA-5 Replication#Leaders and Followers]] did not worry about consensus?
- Manually select new leader -> violates termination
- Automatic leader election and failover -> may cause split brain
Epoch numbering and quorums
Leader uniqueness guarantee in consensus protocols:
- Within a epoch number (ballot number in Paxos, term number in Raft), leader is unique.
- Each leader election is given an incremented epoch number (totally ordered / monotonically increase).
- Leader with higher epoch number wins if conflicts.
How does a leader make decision:
- Before decide anything, check other leader with higher epoch number.
- Collect votes from a quorum of nodes: send proposed value to the other nodes and wait for a quorum of nodes to respond yes.
- The quorum typically consists of a majority of nodes
- Flexible Paxos: Quorum Intersection Revisited: Paxos may use non-intersecting quorums. Majority quorums are not necessary as intersection is required only across phases.
- Node votes yes only if it is not aware of any other leader with a higher epoch.
Key insight:
- 2 rounds of voting: choose leader, and vote on leader's proposal
- quorums for 2 votes must overlap
Looks similar to 2PC, differences are:
- In 2PC, the coordinator is not elected.
- Votes from the majority of nodes VS 2PC requires votes from every participant.
- Recovery process makes nodes consistent after new leader election to ensure safety properties.
Limitations of consensus
Summarize pros of consensus algorithms:
- Bring concrete safety properties to uncertain systems
- Remain fault-tolerant (make progress while majority of nodes alive)
- Provide total order broadcast to implement linearizable atomic operations
What are the cost?
- Voting on proposal before accepting is similar to sync replication, which hurts performance.
- Requiring strict majority means (2n+1) nodes minimum to tolerate n nodes failure. And the cut off portion of the network cannot make progress ([[#The Cost of Linearizability]]).
- Most algorithms assume fixed set of nodes vote. Dynamic membership extension is much less well understood.
- False leader failure detection due to network delays cause performance issues.
More notes on network impact:
Coracle: Evaluating Consensus at the Internet Edge: Our insight is that current consensus algorithms have significant availability issues when deployed outside the well defined context of the data-center.
Figure 3 shows the reachability between 4 hosts, one of which is behind a poorly configured NAT, allowing it to transmit messages to all hosts but not hear responses.
This host will never be able to hear the leader’s heartbeats and thus will continually timeout, increment its term and start a new election.
When contacting the other hosts, it will remove the current leader and continuously force leader election, rendering the system unavailable.
Membership and Coordination Services
How a service like ZooKeeper or etcd is used?
- Used by other projects in the background.
- Designed to hold small amounts of data in memory, replicated across all the nodes using a fault-tolerant total order broadcast algorithm.
- Applying the same writes (total order broadcast messages) in the same order keeps replicas consistent.
ZooKeeper features
- Linearizable atomic operations: can be used to implement a distributed lock (lease) with expiry time. (only one requires consensus)
- Total ordering of operations: ZooKeeper totally orders all operations with
zxidand version number. These can be used as fencing token ([[DDIA-8 The Trouble with Distributed Systems#Fencing tokens]]). - Failure detection: Clients and ZooKeeper servers exchange heartbeats through long-lived session, if timeout, session held locks can be configured to be auto released.
- Change notifications: clients can read locks and values being written. Useful for knowing the other client joins or fails.
Combining these features, ZooKeeper can be very useful for distributed coordination.
Allocating work to nodes
Examples:
- Select a leader from several instances of a process or service, useful in single-leader databases, job schedulers and similar stateful systems.
- Decide which partition to assign to which node, rebalance when nodes join or fail/removed.
Use atomic operations, ephemeral nodes and notification in ZooKeeper can achieve auto recover from faults without human intervention.
ZooKeeper usually run on a small (3/5) fixed number of nodes to support potentially large number of clients. It provides a way of "outsourcing" some of the work of coordinating nodes to an external service.
Data managed by ZooKeeper is slow-changing (in minutes or hours). For replicating runtime state, use tools like Apache BookKeeper.
Service discovery
Solves the problem that virtual machines continually come and go in cloud environments, and you don't know the IP address of your services.
Solution is to configure your services such that when they start up they register their network endpoints in a service registry, where they can then be found by other services.
Leader election requires consensus, consensus system can help other services know who the leader is. Async replica do not vote but can serve read requests that do not need to be linearizable.
Note: using ZooKeeper for service discovery means when network partitions, other services can't get response back. If availability is preferred, Eureka might be better option.
Membership services
A membership service determines which nodes are currently active and live members of a cluster. By coupling failure detection with consensus, nodes can come to an agreement about which nodes should be considered alive or not.
- Previous: DDIA Chapter 7. Transactions
- Next: Continuous Integration at Google